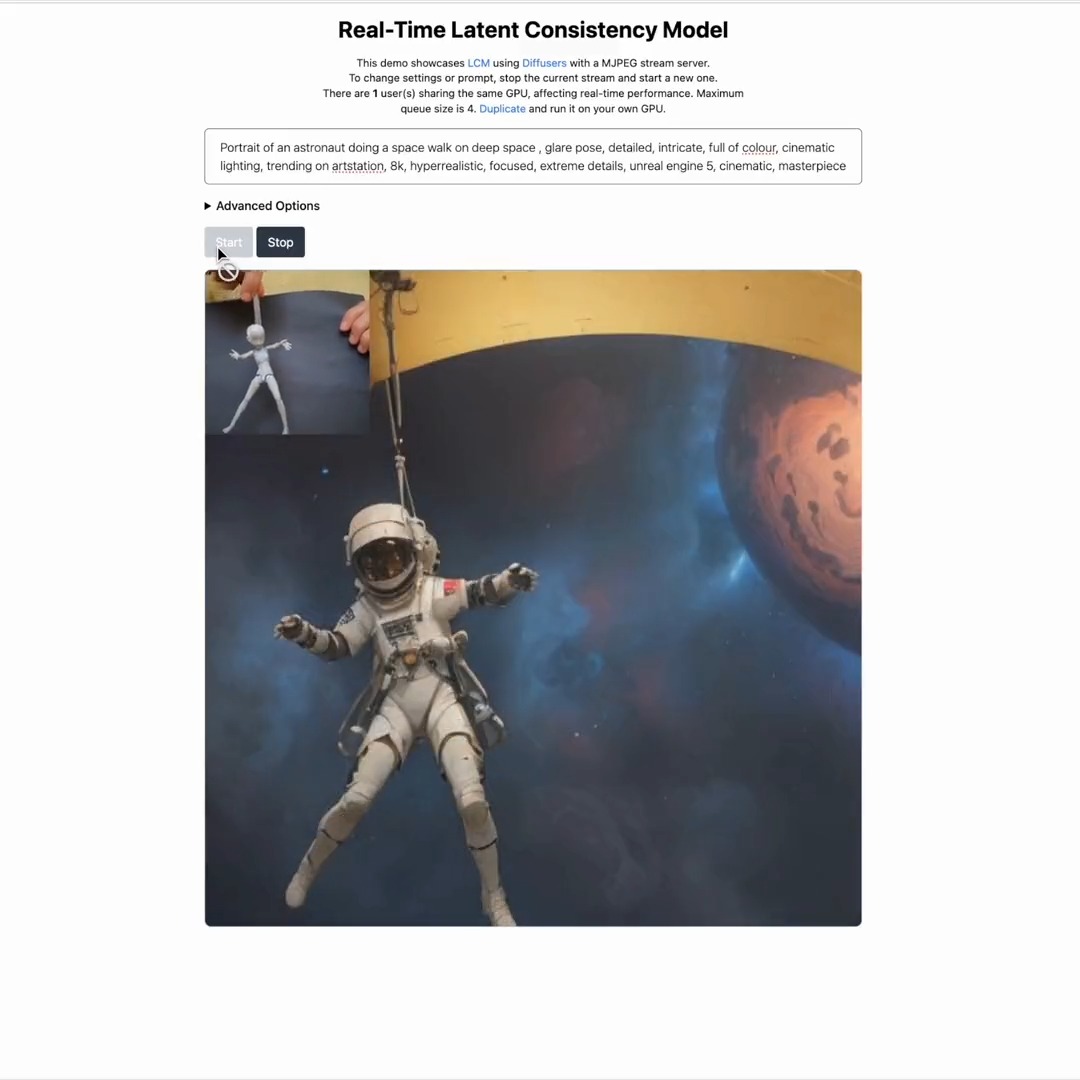
Video wird geladen...
Video konnte nicht geladen werden
Large Language Diffusion with Masking (LLaDA) are here - and their generation looks so fucking dope! 🤯 True to Yann LeCun's vision, Ditch the auto-regressive bits and approximate the language distribution via Maximum Likelihood Estimation! So cool to watch the model denoise text from tokens in real time! -... show more

21,394 Aufrufe • vor 1 Jahr •via X (Twitter)
12 Kommentare

Check out the demo here:
Model checkpoints here:

Announcing: Our most advanced speech-to-text model goes beyond accuracy to capture the real-world complexity of human conversation and deliver reliable, source-of-truth audio data. Explore Universal-2 updates 👇

@ylecun @Stardust_nds check this out buddy , something that we have been discussing about Also LLaDa

@ylecun This is interesting! Finally a new architecture for LLMs. I don't think this solves any of the @ylecun concerns with transformer based Auto Regressive LMs. No world model. No video understanding, etc.
@ylecun Omg , I think this idea is perfect to make the answers more precise, 🥵 hello 100 precision

@ylecun Since you have to compute the whole maximum possible response length every time, what does this mean for VRAM requirements when deploying these models?

@ylecun How does this stack up with Inception?

Llama has now been downloaded over 1 Billion times! A note to: The researchers at Meta training these models — and those building on the research in other labs. The developers and enthusiasts on r/LocalLlama, @huggingface and more; experimenting with new models and creating derivatives. The small startups and big enterprises alike who are creating a new wave of AI-powered products, built with Llama. The global AI community. Your actions speak louder than words, thank you for making it abundantly clear — a billion times over — that open source AI is how we'll create the next wave of world changing technologies, together. 🦙❤️

Coming soon: HunYuan-T1,The first ultra-large Mamba-powered reasoning model! Stay tuned! 🚀

Bytedance just dropped DAPO on Hugging Face An Open-Source LLM Reinforcement Learning System at Scale

Announcing fasttransform: a Python lib that makes data transformations reversible/extensible. No more writing inverse functions to see what your model sees. Debug pipelines by actually looking at your data. Built on multi-dispatch. Work w/ @R_Dimm


![Google presents AudioPaLM: A Large Language Model That Can Speak and Listen paper page: introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt.](https://image.24vids.com/tw-1672048076469698561/ext_tw_video_thumb/1672047839378300928/pu/img/MuoOBsAyUd-HAI7D.jpg)