正在加载视频...
视频加载失败
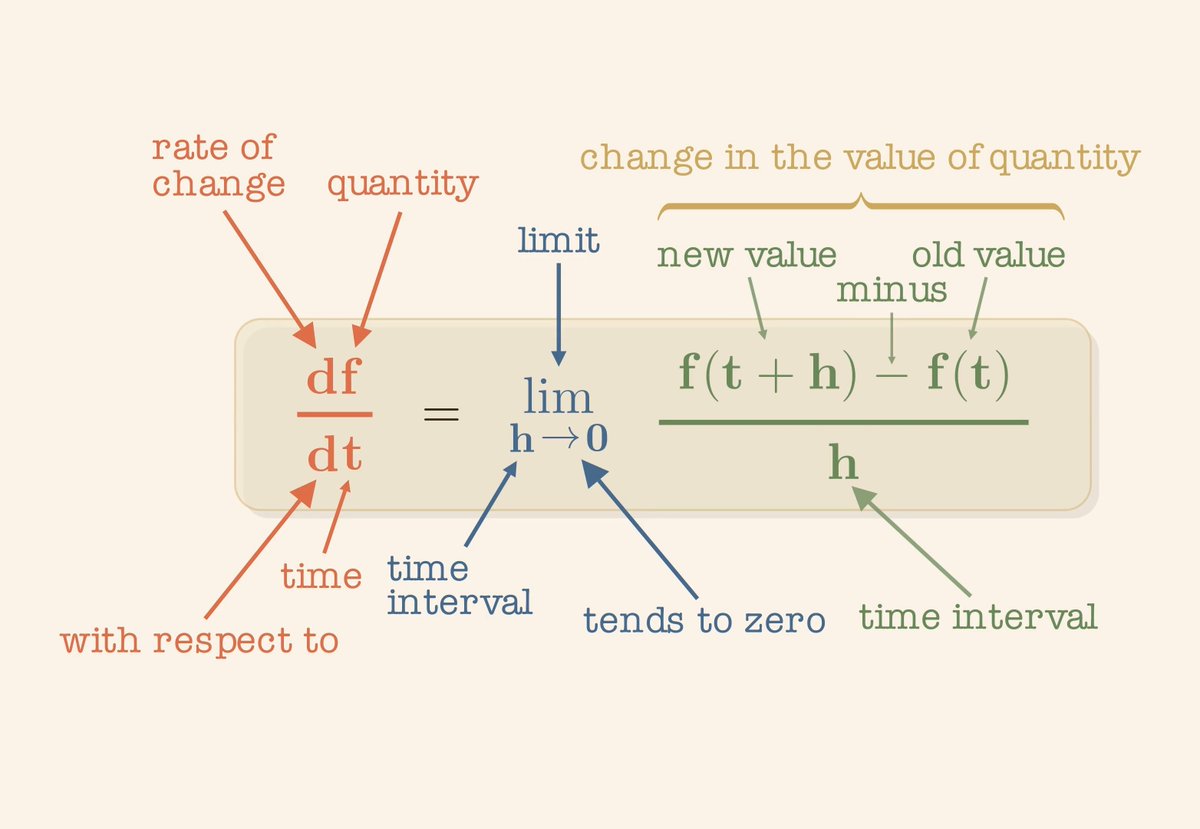
Let me explain the agent loop, simple It's the core of every agentic system, and the part most people overcomplicate It's just this: 1. Send messages to the model 2. Model responds, maybe calls a tool 3. You run the tool 4. Append the result back to messages 5.... show more

12,514 次观看 • 26 天前 •via X (Twitter)
0 条评论
暂无评论
原始帖子的评论将显示在这里