正在加载视频...
视频加载失败
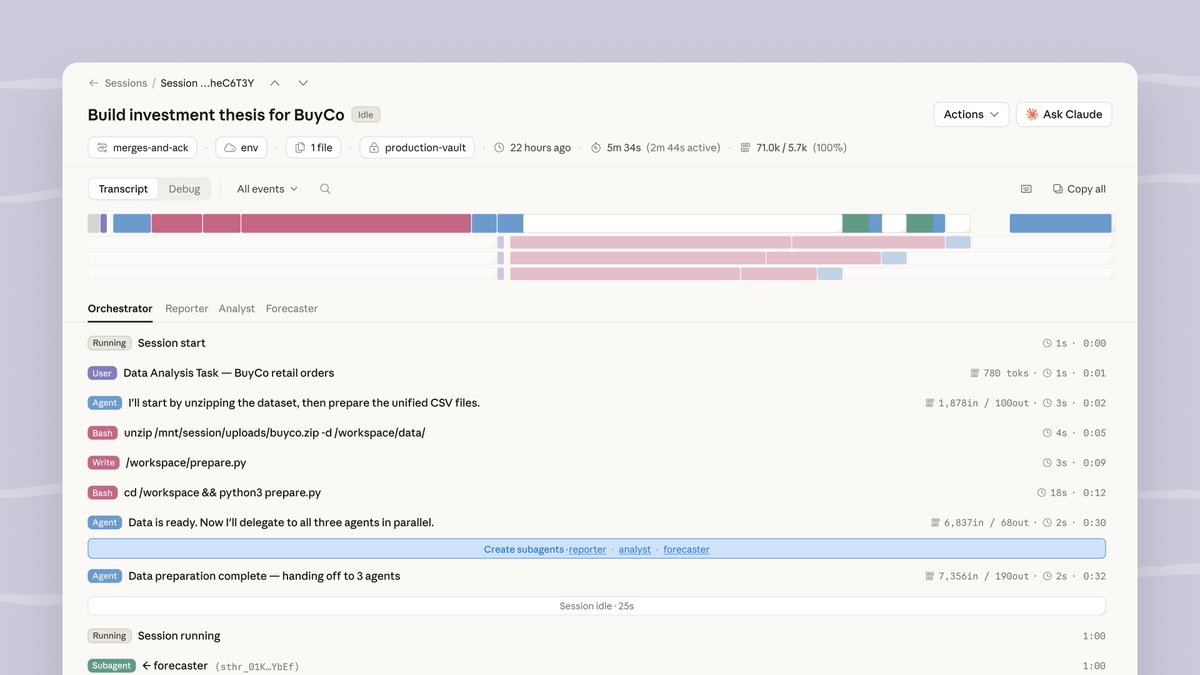
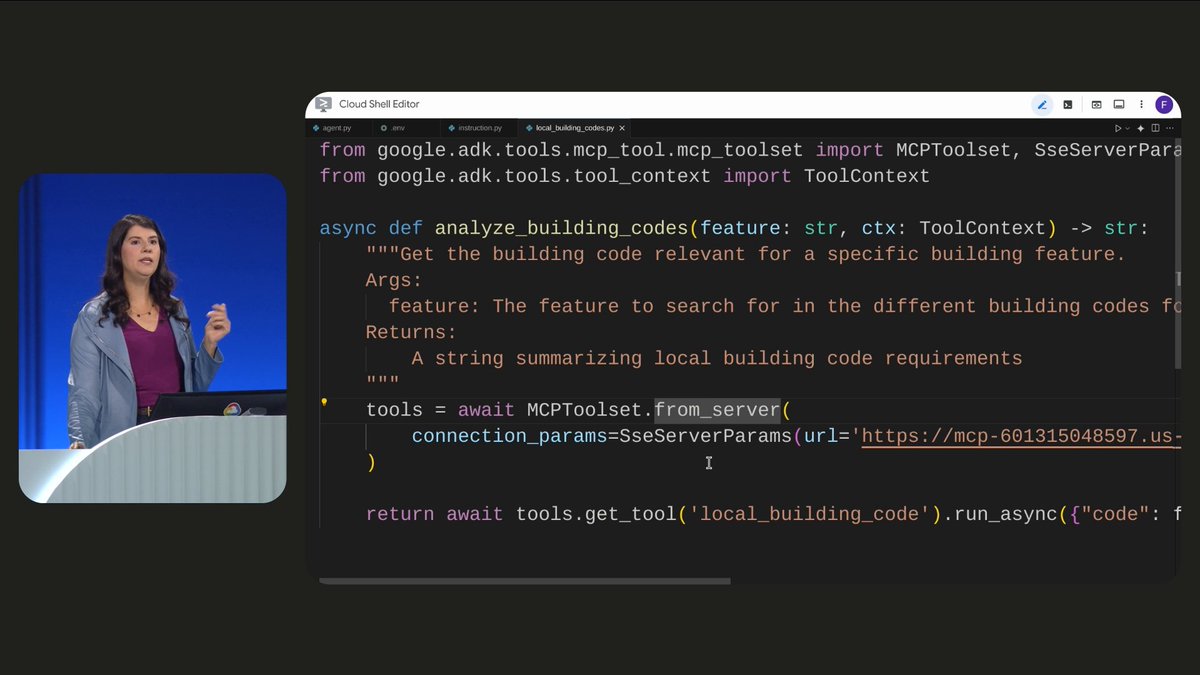
Most agent demos are stateless. Ask → answer → context gone. Production agents need to run for days — pausing, resuming, persisting state. Addy Osmani joins Smitha Kolan on the Agent Factory to build three real agents with ADK 2.0 and Gemini 3.5 Flash, including one that runs Doom... show more

13,311 次观看 • 3 天前 •via X (Twitter)
0 条评论
暂无评论
原始帖子的评论将显示在这里