Awni Hannun
@awnihannun • 44,820 subscribers
ow knee
Shorts













Videos

The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality! The model was quantization aware trained (qat) at int4. Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm:
Awni Hannun500,639 просмотров • 6 месяцев назад







Running Qwen3 8B thinking on an iPhone Air with MLX. The model is quantized to 4-bit and runs pretty well.
Awni Hannun215,529 просмотров • 8 месяцев назад

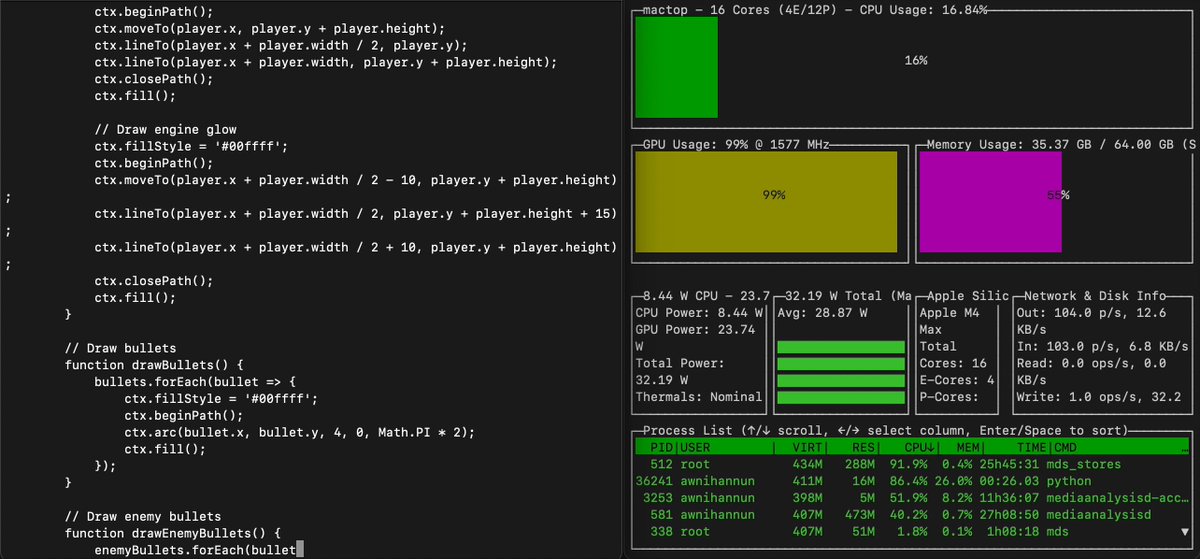
Qwen3-Coder-Flash runs quite fast on an M4 Max with mlx-lm. Running the 4-bit here, generated 4,467 tokens at >107 tokens/sec:
Awni Hannun196,482 просмотров • 10 месяцев назад


Running four simultaneous OpenCode agents works well with mlx_lm.server continuous batching and MiniMax M2.1 on an M3 Ultra:
Awni Hannun95,013 просмотров • 5 месяцев назад

MiniMax M2.1 in 4-bit cruises on an M3 Ultra with mlx-lm. Generated a space invaders game using 5098 tokens at 47.2 tok/sec:
Awni Hannun93,826 просмотров • 5 месяцев назад

GLM-5 runs with mlx-lm on a single 512GB M3 Ultra in Q4. It's quite good in my initial testing and pretty fast as well. It generated a highly functional space invaders game using 7.1k tokens at 15.4 tok/s and 419GB memory. Thanks to Gökdeniz Gülmez and Tarjei Mandt for the port.
Awni Hannun60,446 просмотров • 3 месяцев назад

The new Deep Seek V3 0324 in 4-bit runs at > 20 toks/sec on a 512GB M3 Ultra with mlx-lm!
Awni Hannun168,815 просмотров • 1 год назад


Qwen3.5 runs quite well in mlx-lm. Awesome that we have a frontier-level hybrid model. The context gets longer but the inference speed and memory use barely change. Here's the Q4 generating a space invaders game on an M3 Ultra. Generated 4,120 tokens at 37.6 tok/s.
Awni Hannun46,577 просмотров • 3 месяцев назад