

Dwarkesh Patel
@dwarkesh_sp • 242,385 subscribers
Host of @dwarkeshpodcast https://t.co/3SXlu7fy6N https://t.co/4DPAxODFYi https://t.co/hQfIWdM1Un
Shorts

Videos


Adam Brown (Adam Brown) is back! General relativity is said to be the most beautiful idea the human mind has ever produced. Most of us will never get to fully appreciate its elegance by taking the 20-lecture graduate course Adam taught on it at Stanford. But in the video below, Adam distills the key idea at its heart so clearly and compellingly that even I could keep up lol. At the core of general relativity, Einstein is trying to figure out the principle behind a particular coincidence: that the mass that resists acceleration and the mass that gravity pulls on just happen to be exactly the same. Adam then leads us through the path of insight which Einstein called his “happiest thought.” Then Adam lectures on black holes. First, by showing how even under special relativity you could create a perpetual motion machine if black holes weren't truly black. And then, by explaining why the observations of an infalling observer and a distant bystander to the black hole would be so radically different Adam leads Blueshift, the team at Google DeepMind cracking science and reasoning. Which gave us the opportunity to discuss at the very end how close we are to AIs that could rediscover general relativity from scratch. Stay till the close for some philosophy of science. 0:00:00 – The coincidence that led Einstein to general relativity 0:16:42 – Gravity is a consequence of curved spacetime, not a force 0:31:46 – Why black holes prevent unlimited energy extraction 0:47:12 – Black holes are the ultimate power plants 1:13:50 – What falling into a black hole would actually feel like 1:18:51 – The three ways we know black holes are real 1:24:21 – The first time we saw gravity bend light 1:29:33 – How far can AI get without experimental evidence? Look up Dwarkesh Podcast on YouTube/Spotify to watch. Enjoy!
Dwarkesh Patel633,119 次观看 • 10 天前

The Jensen Huang episode. 0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains? 0:16:25 – Will TPUs break Nvidia’s hold on AI compute? 0:41:06 – Why doesn’t Nvidia become a hyperscaler? 0:57:36 – Should we be selling AI chips to China? 1:35:06 – Why doesn’t Nvidia make multiple different chip architectures? Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
Dwarkesh Patel6,218,467 次观看 • 3 个月前

What does the next training paradigm look like? 0:00:00 – The big research bet the labs are making 0:02:12 – Grindability is just as important as verifiability 0:06:10 – Will RLVR alone generalize? 0:08:41 – Getting the learning back to the weights 0:15:22 – Dreaming 0:17:23 – What 2027 looks like Also on YouTube, pod feed, and Substack.
Dwarkesh Patel740,819 次观看 • 24 天前

The Andrej Karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self driving took so long 1:57:08 - Future of education Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
Dwarkesh Patel10,756,105 次观看 • 9 个月前

I asked Dario 3 years ago why AIs haven't been able to use their vast knowledge across so many fields to connect two known ideas into a new discovery. It seems like AI did exactly this in the way it disproved Erdos' conjecture aobut the unit distance problem by cleverly onnecting together ideas in discrete geometry and algebraic number theory. Now that AI has been able to use its knowledge across multiple fields to come up with new ideas, what is the next benchmark? Grant Sanderson proposed one during our interview: "Good mathematicians prove theorems, great mathematicians come up with conjectures, and the greatest mathematicians come up with definitions."
Dwarkesh Patel314,951 次观看 • 18 天前

.John Collison and I interviewed Elon Musk. 0:00:00 - Orbital data centers 0:36:46 - Grok and alignment 0:59:56 - xAI’s business plan 1:17:21 - Optimus and humanoid manufacturing 1:30:22 - Does China win by default? 1:44:16 - Lessons from running SpaceX 2:20:08 - DOGE 2:38:28 - TeraFab
Dwarkesh Patel3,544,009 次观看 • 5 个月前
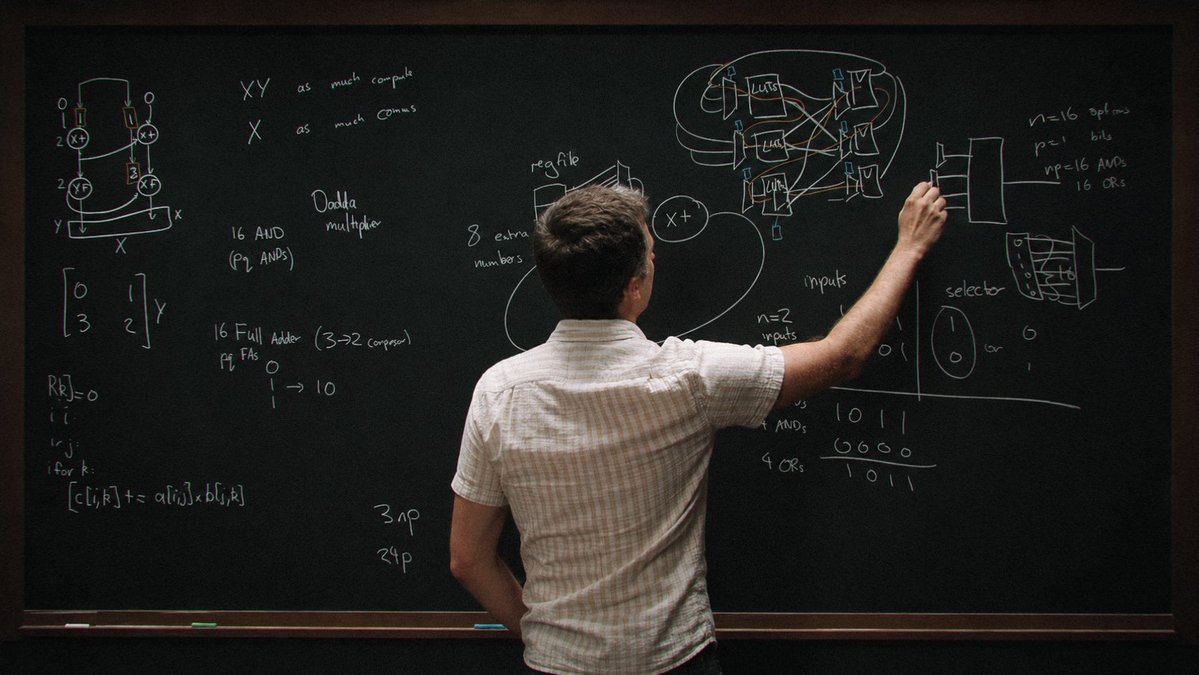
New blackboard lecture w Reiner Pope How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do. 0:00:00 – Building a multiply-accumulate from logic gates 0:16:20 – Muxes and the cost of data movement 0:25:59 – How systolic arrays work 0:39:00 – Clock cycles and pipeline registers 0:51:40 – FPGAs vs ASICs 1:03:14 – Cache vs scratchpad 1:07:16 – Why CPU cores are much bigger than GPU cores 1:11:49 – Brains vs chips 1:15:22 – A GPU is just a bunch of tiny TPUs Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
Dwarkesh Patel933,783 次观看 • 1 个月前

Always so much fun to chat with Grant Sanderson AI has been making much faster progress in math than in other fields. As a result, mathematics is showing us, very concretely, what AI progress in other fields will look like. Even within mathematics, there's a jagged landscape. What does it look like? What is the nature of the most important conceptual breakthroughs in the history of mathematics, and how different are they from what AIs are currently able to do? Does AI (on net) increase or decrease human understanding of the field? How big is the overhang from having AIs systematically try to connect ideas already in the literature? And what advice does Grant have for aspiring mathematicians, coders, and other students who are passionate about fields that are being most transformed upon by AI? 0:00:00 – AI is discovering new proofs. Is that AGI? 0:11:32 – The verification loop on conceptual breakthroughs can be a century long 0:26:12 – Will we understand an AI proof of the Riemann hypothesis? 0:38:08 – Can AI find the hidden bridges between fields? 0:53:48 – Why real-world tasks don’t fit into RL environments 1:07:07 – Good writing requires theory of mind that AI still lacks 1:16:02 – Why learning will still depend on human curation Look up Dwarkesh Podcast on Spotify, Apple Podcasts, YouTube, etc.
Dwarkesh Patel286,538 次观看 • 20 天前

Did a very different format with Reiner Pope – a blackboard lecture where he walks through how frontier LLMs are trained and served. It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk. It’s a bit technical, but I encourage you to hang in there - it’s really worth it. There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him. Recommend watching this one on YouTube so you can see the chalkboard. 0:00:00 – How batch size affects token cost and speed 0:31:59 – How MoE models are laid out across GPU racks 0:47:02 – How pipeline parallelism spreads model layers across racks 1:03:27 – Why Ilya said, “As we now know, pipelining is not wise.” 1:18:49 – Because of RL, models may be 100x over-trained beyond Chinchilla-optimal 1:32:52 – Deducing long context memory costs from API pricing 2:03:52 – Convergent evolution between neural nets and cryptography
Dwarkesh Patel1,287,923 次观看 • 2 个月前

The Ilya Sutskever episode 0:00:00 – Explaining model jaggedness 0:09:39 - Emotions and value functions 0:18:49 – What are we scaling? 0:25:13 – Why humans generalize better than models 0:35:45 – Straight-shotting superintelligence 0:46:47 – SSI’s model will learn from deployment 0:55:07 – Alignment 1:18:13 – “We are squarely an age of research company” 1:29:23 – Self-play and multi-agent 1:32:42 – Research taste Look up Dwarkesh Podcast on YouTube, Apple Podcasts, or Spotify. Enjoy!
Dwarkesh Patel4,126,983 次观看 • 7 个月前

Jensen on the famous story about Larry Ellison and Elon Musk begging him for GPUs over dinner: "That never happened. We absolutely had dinner, and it was a wonderful dinner. At no time did they beg for GPUs. They just had to place an order." Jensen says Nvidia's allocation system is simple: you forecast, you place a purchase order, you get in the queue. First in, first out. And if your data center isn't ready, they might serve someone else first to maximize throughput. That's it. Nvidia doesn’t do highest-bidder pricing: "You set your price, and then people decide to buy it or not. I understand that others in the chip industry change their prices when demand is higher, but we just don't. That's just never been a practice of ours." "I prefer to be dependable, to be the foundation of the industry. You don't need to second-guess. If I quoted you a price, we quoted you a price. And if demand goes through the roof, so be it."
Dwarkesh Patel1,312,775 次观看 • 3 个月前

Distilled recap of the back-and-forth with Jensen on export controls: Dwarkesh: Wouldn’t selling Nvidia chips to China enable them to train models like Claude Mythos with cyber offensive capabilities that would be threats to American companies and national security? Jensen: First of all, Mythos was trained on fairly mundane capacity and a fairly mundane amount of it by an extraordinary company. The amount of capacity and the type of compute it was trained on is abundantly available in China. Dwarkesh: With that, could they eventually train a model like Mythos? Yes. But the question is, because we have more FLOPs, American labs are able to get to this level of capabilities first. Furthermore, even if they trained a model like this, the ability to deploy it at scale matters. If you had a cyber hacker, it's much more dangerous if they have a million of them versus a thousand of them. Jensen: Your premise is just wrong. The fact of the matter is their AI development is going just fine. The best AI researchers in the world, because they are limited in compute, also come up with extremely smart algorithms. DeepSeek is not an inconsequential advance. The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation. Dwarkesh: Currently, you can have a model like DeepSeek that can run on any accelerator if it's open source. Why would that stop being the case in the future? Jensen: Suppose it optimizes for Huawei. Suppose it optimizes for their architecture. It would put others at a disadvantage. As AI diffuses out into the rest of the world, their standards and their tech stack will become superior to ours because their models are open. Dwarkesh: Tesla sold extremely good electric vehicles to China for a long time. iPhones are sold in China. They didn't cause some lock-in. China will still make their version of EVs, and they're dominating, or smartphones, they're dominating. Jensen: We are not a car. The fact that I can buy this car brand one day and use another car brand another day is easy. Computing is not like that. There's a reason why x86 still exists. There's a reason why Arm is so sticky. These ecosystems are hard to replace. Dwarkesh: It's just hard to imagine that there's a long-term lock-in to the Chinese ecosystem, even if they have this slightly better open-source model for a while. American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips. Jensen: China is the largest contributor to open source software in the world. China's the largest contributor to open models in the world. Today it's built on the American tech stack, Nvidia’s. Fact. All five layers of the tech stack for AI are important. The United States ought to go win all five of them. in a few years time, I'm making you the prediction that when we want American technology to be diffused around the world—out to India, out to the Middle East, out to Africa, out to Southeast Asia—on that day, I will tell you exactly about today's conversation, about how your policy ... caused the United States to concede the second largest market in the world for no good reason at all.
Dwarkesh Patel1,250,786 次观看 • 3 个月前

The Dario Amodei interview. 0:00:00 - What exactly are we scaling? 0:12:36 - Is diffusion cope? 0:29:42 - Is continual learning necessary? 0:46:20 - If AGI is imminent, why not buy more compute? 0:58:49 - How will AI labs actually make profit? 1:31:19 - Will regulations destroy the boons of AGI? 1:47:41 - Why can’t China and America both have a country of geniuses in a datacenter? Look up Dwarkesh Podcast on Youtube, Spotify, Apple Podcasts, etc.
Dwarkesh Patel2,057,625 次观看 • 5 个月前

There's a quadrillion-dollar question at the heart of AI: Why are humans so much more sample efficient compared to LLM? There are three possible answers: 1. Architecture and hyperparameters (aka transformer vs whatever ‘algo’ cortical columns are implementing) 2. Learning rule (backprop vs whatever brain is doing) 3. Reward function Adam Marblestone believes the answer is the reward function. ML likes to use pretty simple loss functions, like cross-entropy. These are easy to work with. But they might be too simple for sample-efficient learning. Adam thinks that, in humans, the large number of highly specialised cells in the ‘lizard brain’ might actually be encoding information for sophisticated loss functions, used for ‘training’ in the more sophisticated areas like the cortex and amygdala. Like: the human genome is barely 3 gigabytes (compare that to the TBs of parameters that encode frontier LLM weights). So how can it include all the information necessary to build highly intelligent learners? Well, if the key to sample-efficient learning resides in the loss function, even very complicated loss functions can still be expressed in a couple hundred lines of Python code.
Dwarkesh Patel948,899 次观看 • 2 个月前


New blackboard lecture w Eric Jang He walks through how to build AlphaGo from scratch, but with modern AI tools. Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn. Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second. Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside. Timestamps: 0:00:00 – Basics of Go 0:08:06 – Monte Carlo Tree Search 0:31:53 – What the neural network does 1:00:22 – Self-play 1:25:27 – Alternative RL approaches 1:45:36 – Why doesn’t MCTS work for LLMs 2:00:58 – Off-policy training 2:11:51 – RL is even more information inefficient than you thought 2:22:05 – Automated AI researchers
Dwarkesh Patel703,166 次观看 • 2 个月前

.Richard Sutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled. My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning. And if we have continual learning, we don't need a special training phase - the agent just learns on-the-fly - like all humans, and indeed, like all animals. This new paradigm will render our current approach with LLMs obsolete. I did my best to represent the view that LLMs will function as the foundation on which this experiential learning can happen. Some sparks flew. 0:00:00 – Are LLMs a dead-end? 0:13:51 – Do humans do imitation learning? 0:23:57 – The Era of Experience 0:34:25 – Current architectures generalize poorly out of distribution 0:42:17 – Surprises in the AI field 0:47:28 – Will The Bitter Lesson still apply after AGI? 0:54:35 – Succession to AI
Dwarkesh Patel3,081,359 次观看 • 9 个月前

Recently met Sasha Rush and he started giving me an impromptu lecture on how targeted on-policy self-distillation works. I asked him if I could record it on my iPhone. The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory. So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made. Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required. The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
Dwarkesh Patel426,939 次观看 • 1 个月前

Gutenberg invented the most important technology of the millennium and immediately went bankrupt — and so did the bank that foreclosed on him, and so did his apprentices. Gutenberg could make a batch of 300 books for the cost of one, but there weren't enough buyers in his small, landlocked village in Germany. It it took the better part of a century of further innovations, social changes, and setting up of distribution networks before you could have a pamphlet like Luther's 95 thesis get from Wittenberg to London in 17 days.
Dwarkesh Patel1,245,758 次观看 • 4 个月前