Loading video...
Video Failed to Load
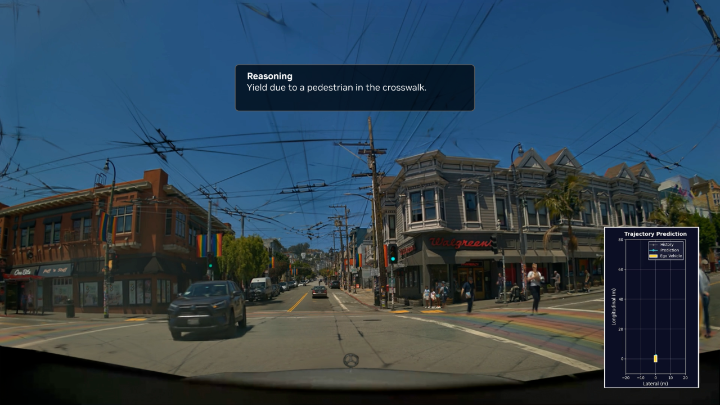
Large language models reason through text. Vision‑language‑action models reason through the real world. By fusing perception, context, and action from live video, VLAs deliver the awareness physical AI needs for next‑gen robotics and edge systems.

15,931 views • 5 months ago •via X (Twitter)
0 Comments
No comments available
Comments from the original post will appear here