Video yükleniyor...
Video Yüklenemedi
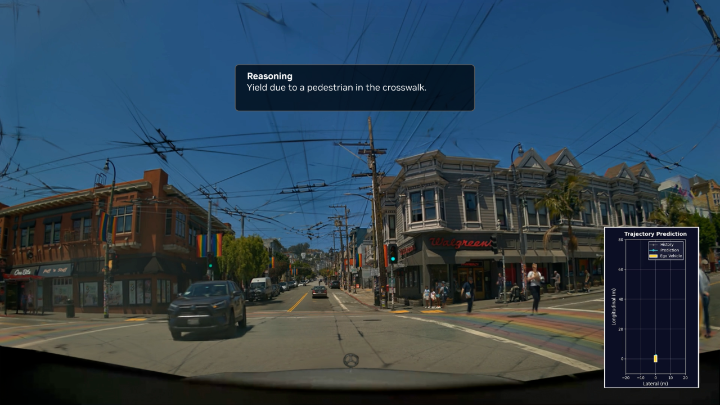
Large language models reason through text. Vision‑language‑action models reason through the real world. By fusing perception, context, and action from live video, VLAs deliver the awareness physical AI needs for next‑gen robotics and edge systems.

15,931 görüntüleme • 3 ay önce •via X (Twitter)
0 Yorum
Yorum bulunmuyor
Orijinal gönderinin yorumları burada görünecek