正在加载视频...
视频加载失败
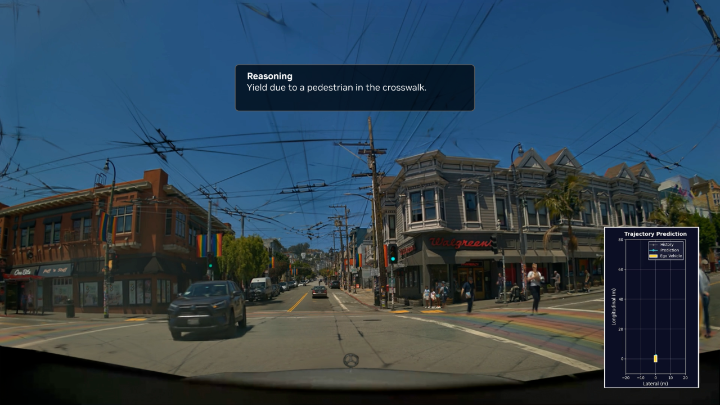
Large language models reason through text. Vision‑language‑action models reason through the real world. By fusing perception, context, and action from live video, VLAs deliver the awareness physical AI needs for next‑gen robotics and edge systems.

15,931 次观看 • 3 个月前 •via X (Twitter)
0 条评论
暂无评论
原始帖子的评论将显示在这里