

Pablo Vela
@pablovelagomez1 • 2,789 subscribers
I like to make computers see. Currently at @rerundotio
Shorts










Videos

Recently, I've been playing with my iPhone ToF sensor, but the problem has always been the abysmal resolution (256x192). The team behind DepthAnything released PromptDepthAnything that fixes this. Using polycam to collect the raw data, Gradio to generate a UI, and Rerun to visualize. Links at the end of the thread
Pablo Vela244,728 次观看 • 1 年前

There's been a few cool updates recently. In particular, Rerun 0.33 released headless rendering. This, along with the Fable 5 release pushed me to work torwards making MAMMA realtime! I threw Fable at the problem, and it was able to take original implementation that was ~12 seconds / frame and get it all the way down to 40ms /frame, or nearly a 300x speedup 🏎️ How did I achieve this? TLDR: - Use rerun's headless rendering as supervision when optimizing - Save rrd file as test fixture to guide model optiziation with /goal - create an html artifact with headless rendering to provide detailed breakdown of what it did and how it actually looks like in the viewer There were a few critical bits to make sure that this ACTUALLY worked and that Fable didn't just cheat or delete something and declare victory. The first is that the original version used Rerun, this allowed us to save things to disk as an RRD file, meaning we could query the contents and use this as a sort of test fixture or golden artifact that held EXACTLY what all of the values should be. Then we can use this with /goal as a metric when doing the optimization to ensure there are no regressions. The second bit is the headless rendering, this gave us the ability to check that not only did the test fixture pass, but it also looked visually correct. This made a huge difference, and an awesome side affect of it is that we can use the headless rendering to create an implementations.html file. This gives a visual guide as to what the agent did (I walk through it in the video below) Along with this, we're working on an MCP server for rerun that allows full interactivity with the rerun viewer for your agent. So for example the agent can click, drag, move views, scroll timelines, ect. I used this to help the agent debug certain parts such as when the 2d sam masks didn't line up, or if the triangulated keypoints werent correctly matching with the optimized mesh. The agents could go, click into the view, scroll through the timeline and see where things went wrong. Fable + Headless Rendering + Rerun MCP == 300x speedup in less then a days work With these new tools, I'm planning on going back to my gaussian splatting implemntation and cleaning it up + making it fast!
Pablo Vela22,771 次观看 • 1 个月前

I've been on a SLAM/SFM kick. It's one of the more underexplored and lacking areas when it comes to human teleop/data collections, so I've brought over Deep Patch Visual Odometry/SLAM to Rerun and Gradio. With this example, we now have 1. pycuvslam 2. pycolmap/glomap 3. mast3r-slam 4. dpvo/slam all integrated into rerun. The question becomes, which method should be used in what situations? They all make different trade-offs with different camera requirements and throughput/accuracy. What about when a new method comes out? Now that I have several different methods, I plan to use VSLAM-LAB for evaluation. It uses prefix.dev to isolate all the dependencies of each of these methods and easily compare them against each other. In particular, I'll be converting the data preprocessing, algorithm outputs, and evaluation into rerun recordings (rrd files). This will allow both programmatic querying of anything stored in the files (which method had the highest ATE-to-FPS ratio? Which dataset/sequence caused the most difficulty? etc. etc.), all with easy visual inspection using the rerun server to link them all together. Another really important side effect of this is how it impacts agents. As Karpathy said ``` LLMs are exceptionally good at looping until they meet specific goals, and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria, and watch it go. ``` by having accuracy and throughput metrics deeply tied with human inspectable artifacts. One can really accelerate agentic development with an actual understanding of how the method/data performs. I think this is another killer use case that I'll be really leaning into to make ingestion of new datasets/methods trivial with an agent. I'm making it my mission for folks to understand that rerun as a visualization tool only scratches the surface of what its true benefit is. Deep integration between data and visuals, with powerful query capabilities. I'll be focusing on the SLAM use case first and then bringing this into the full egocentric/exocentric data collection domain!
Pablo Vela40,864 次观看 • 3 个月前

I've migrated the old Mast3r-SLAM example I had made last year to the latest version of Rerun and made a bunch of improvements! I wanted to spend some time with agents to modernize it. Here's an example of me walking around with my iPhone and getting a dense reconstruction at about 10FPS on a 5090. Heres the following improvements I made. Brought it into the monorepo with proper packaging: • Using prefix.dev pixi-build to get rid of all the mast3r/asmk/lietorch vendored code with just a few small patches. This let me remove so 60k lines of code from the repo! • Don't have to build the lietorch code on my machine anymore, which was taking ~10 minutes to compile (and also made it work on blackwell when it previously did not) Rebuilt the Gradio interface: • Fixed incremental updates, .MOV uploads, and stop behavior • Made the CLI + Gradio interface share the same entry point so updates automatically propagate Upgraded the Rerun integration: • Switched to a multiprocessing async logging strategy • Added video/pointmap/confidence logging • Improved blueprint layout and hid noisy entities from 3D view • Biggest perf win was the async background logger - documented about a ~2.5x speedup from decoupling logging from tracking The newest and most interesting part was my attempt to replace the CUDA kernels for Gauss-Newton ray matching with a Modular Mojo backend. As a Python dev, every time I look at CUDA code I basically shy away as it's pretty difficult for me to understand. Mojo let me rewrite the matching logic in a syntax I'm more comfortable with while still getting near-CUDA performance. Mojo is now the default matching backend with CUDA fallback. One major piece that's missing is the custom PyTorch op path, but I'll eventually do that as well. I heavily leaned on Claude Code to do the CUDA → Mojo migration, and I have no doubt it's not the cleanest or most idiomatic, BUT it's way more readable for me and helps me better understand the underlying algorithm. This was a ton of work, and a large part of why I'm doing it is how the monorepo compounds. This becomes an artifact for the next example I want to build with Claude that I can point to, which will make it even faster to implement. The compounding nature of this is really interesting and part of why I'm spending so much time trying to make things nice and readable.
Pablo Vela42,143 次观看 • 3 个月前

Most people think Rerun is a visualization tool. In reality, it's a database masquerading as a visualizer. I wanted to showcase this functionality by building a full data pipeline consisting of: ingestion → baseline method → eval → finetuning for SLAM on egocentric data. I'll eventually extend this to the rest of my ego/exo datasets, but I wanted to start with a smaller bunch of datasets first. Rerun allows you to expose your saved .rrd files to a catalog where you store datasets. You can query, filter, and join them like any database using DataFusion under the hood. These are the same .rrd files that are automatically generated whenever you visualize anything in Rerun and decide to save it to disk. I brought in 109 VSLAM-LAB sequences across 14 datasets into the Rerun catalog as an example. These include 7Scenes, Euroc, eth3d, and others. Now I can query them with segment_table, filter_segments, and filter_contents instead of parsing CSVs and YAML files. With a strong set of ground-truth datasets for SLAM, baseline additions become nearly automatic with agents like Opus/Codex. This unification of data and visualization is imo the largest missing part for Physical AI. Visualization becomes a natural byproduct of having your data properly structured and queryable. The catalog API is what makes it a database, not just a viewer. I initially focused on VSLAM-LAB data, but I'll migrate all the egoexo data to this format in the coming days to really show just how useful this is.
Pablo Vela34,937 次观看 • 2 个月前

We have SLAM on the Robocap! 🎉 Visualized with Rerun Using NVIDIA AI Developer cuVSLAM for GPU-accelerated multicamera tracking. I basically wrote zero code myself and fully used Claude Code for this. It worked because I had so many existing examples to point to that it just wrote everything the way I would have. A few technical wins: 1. Used rattler-build from prefix.dev to package the compiled cuVSLAM CUDA binaries, which made it SUPER easy to use across repos. This also means it works on the DGX Spark (ARM64) out of the box. 2. Zero-setup experience: git clone && pixi run track-robocap auto-downloads a 100MB dataset from HuggingFace and tracks frames. 3. Real-time 3D visualization with trajectories, landmarks, pose graphs, and video playback in Rerun. Still visual-only (not visual-inertial yet), and loop closure needs some debugging. Next steps are getting this into a Gradio interface, then into daggr, and extending it to work with other datasets from exoego-forge. The last piece I'm excited about: Rerun's RRD files now support layers for incremental data. Planning to build pipelines that go from raw sensor data → slam -> human pose → depth estimation → etc. Repo here:
Pablo Vela50,805 次观看 • 4 个月前

We have HOT3D! I've started using Claude to port more datasets into Rerun and exoego-forge. I'd been meaning to bring in the HOT3D dataset from Meta for a while, but with Claude, it's way easier. My goal is to take any egocentric, exocentric, or both datasets and ingest them into a standardized schema. Getting everything into Rerun means we can easily query and transform data via the in-memory OSS server. This lets us generate SQL-like queries such as: "Find me all frames that only contain left hands in the leftmost camera view." Most people think of Rerun as a viewer, but this is the actual superpower. So far we have: 1. HOT3D 2. Hocap 3. UmeTrack 4. Assembly101 5. EgoDex Planning to add more, and with every addition, it gets easier as we build up agent skills and better code examples. Hoping to make it almost fully automatic for adding new datasets. The next few I'm looking at are Harmony4D and Aria Pilot Gen2 After we have enough samples, I'll work on bringing in all the different algorithms I've worked on to transform the data 🙂
Pablo Vela35,662 次观看 • 3 个月前
Colmap 4.0 was very recently released, so it inspired me to do some work to better understand it and its new capabilities with Rerun. I want to really understand how Colmap, and in particular, pycolmap, works outside of just calling it via the CLI. So my goal is to use the low-level pycolmap API to log every part of the pipeline. The explicit goal is to have an alternative to the SQLite database that I can utilize. Instead of SQLite, I want to try logging everything directly to rerun and use RRD. This means I can have deep inspectability and still save the features/matches/2D view geometry, but be able to view it directly in rerun. I think this is one of the superpowers that rerun provides; data and visualizations are deeply integrated. As I'm often working with sequential data (videos), I'm going to specifically focus on four things: 1. Monocular Video Simple: Calls high-level APIs such as pycolmap.extract_features, pycolmap.match_sequential, pycolmap.incremental_mapping. These are basically identical to the CLI options and provide a good baseline. 2. Monocular Video Streamed: Take the above high-level APIs and break them down to their iterator version, logging each component in a streamed manner. This way, I can stream the intermediate features to rerun while the extraction/matching/mapping is happening. 3. Rig with unknown calibration: <- WHAT THE VIDEO SHOWS This is probably the most interesting version and the first one I've been working on. It allows one to set a rig between known sensors, such as in VR/AR devices, leading to much better reconstructions with multiple cameras. This is the case where we don't know the calibration a priori, so we have to run a reconstruction twice: once as a normal Colmap reconstruction with no rig constraints, use this to generate the constraints, and then do it again with the newly found rig. 4. Rig with known calibration: This is the RoboCap example, where we have a pre-calibrated set of sensors, so we don't need to run the two reconstructions and also gain better matching between cameras, both spatially and temporally. Again, this leads to a much better reconstruction! Along with all this, GLOMAP has become a first-class global mapper, making it super easy to use directly within pycolmap! I'm excited to do more with this and compare it to things like pycuvslam, vipe, and other alternatives.
Pablo Vela30,070 次观看 • 3 个月前

Spent last week in Stockholm meeting the Rerun team in person for the first time! While I was there, I got to work on something I've wanted for a while: face culling for 3D reconstructions. Still in main (not deployed yet), but here's a sneak peek of scanning the library we hung out in. Being able to see inside meshes while reconstructing makes it way easier to verify coverage and quality.
Pablo Vela19,890 次观看 • 4 个月前

0.32 has shipped, and it's a massive release from Rerun. There's a ton of cool new features, and I wanted to highlight 2 in particular 1. OSS Server streaming from disk 2. Dataset review I walk you through them in the video, so take a look. I'll have a much longer blog post next week about the entire pipeline. With 0.32, much of the foundation is set for a unified data layer for physical data, and I'll be getting into the details of it with all that I've built over the past year. This will cover 1. Raw Data Collection 2. Data Ingestion 3. Catalog Registration 4. Query and Review 5. Post Process 6. Training so lots to share
Pablo Vela11,264 次观看 • 2 个月前
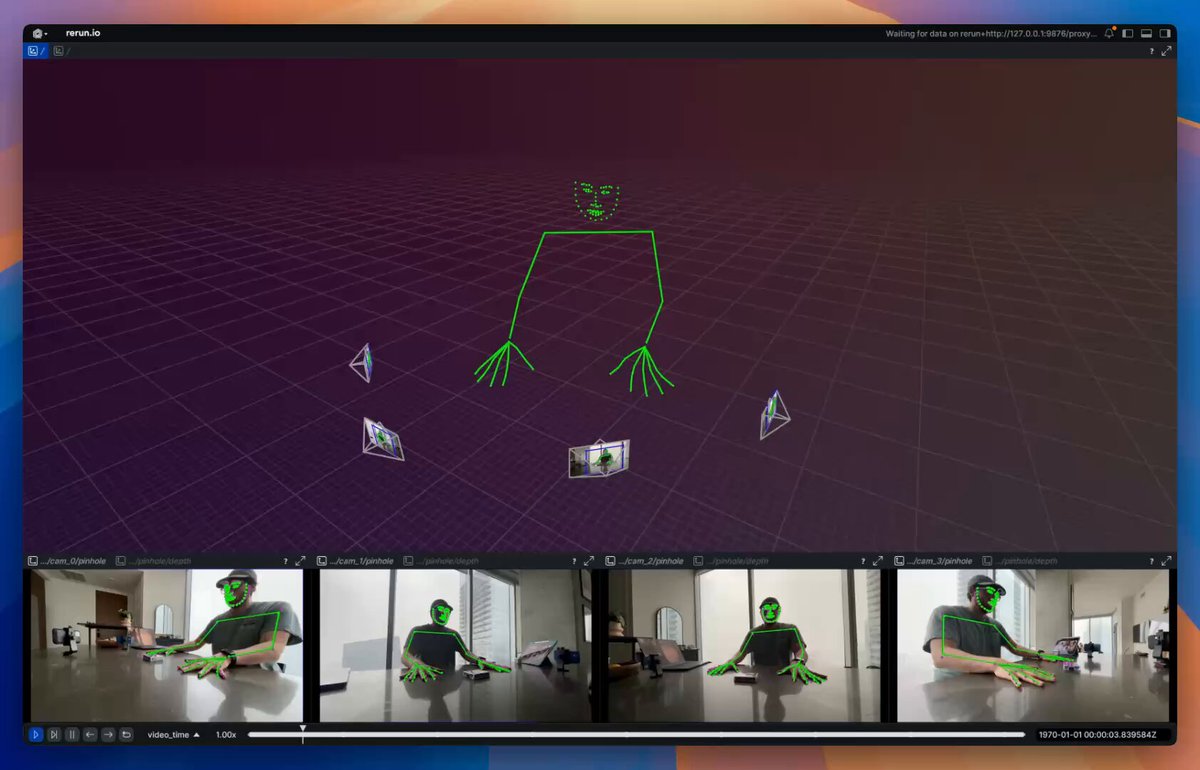
MVP of Multiview Video → Camera parameters + 3D keypoints. Visualized with Rerun The basic pipeline as of right now looks like this: 1. Capture 🔴 – Using 4 iPhones and an Insta360 Go. iPhone videos are captured via Final Cut Pro Multicam for easy sync and the exocentric view; the Insta360 Go is used for the egocentric view. 2. Sync 🕒 – Custom Gradio app using two Rerun viewers and callbacks for easily aligning frame timestamps so the ego and exo views are aligned. 3. Calibrate 🎯 – Use VGGT from Jianyuan and AI at Meta to get intrinsics/extrinsics for sparse cameras. 4. Estimate 3D 🕺 – Use RTMLib whole‑body keypoint estimator on each frame, then triangulate in 3D. What's missing? 1. No temporal coherence: I’m estimating keypoints one frame at a time and one camera at a time. This leads to a lot of jittering. For now, I plan on adding a One Euro Filter to help with jittering. Long term, I'd want to train a multiview keypoint estimator 2. Kinematic fitting is still missing; this is my next goal. The output will be joint angles, as explored in my previous posts. 3. Missing dense point cloud: VGGT seems to fail for me here. I’m looking to explore using MP‑SFM as a method for generating dense multiview depth maps + normals (plus it has a friendlier license compared to VGGT). 4. Eventually, creation of 4D Gaussian splatting using something akin to DN‑splatter—my long‑term goal is a data engine that provides poses/depths/splats/keypoints/etc.
Pablo Vela42,785 次观看 • 1 年前


Working on adding a new dataset to the lineup. Ported ego-dex over to Rerun With rerun now stabilizing RRD format between versions (0.23 -> 0.24), this is the perfect time to start encoding all of the datasets I've been using to RRD 1. I'm starting with ego-dex and then adding others, such as HOCAP/Assembly 101 2. Looking to see if it also makes sense to port to webdatasets RRD 3. I've started including visualizing confidence — green (high), yellow (medium), red (low). More info on Friday
Pablo Vela34,253 次观看 • 1 年前


More progress! I now have two Dockerized Gradio | Rerun apps. The first one takes as input a "raw" rrd file that consists of the synchronized egocentric and exocentric MP4 files. This runs the pipeline and produces an "annotated" rrd file. This has the camera parameters, 3D joints, and projected 2D joints (with 6DOF mano soon). The second app takes this "annotated" rrd file and allows for manual labeling. This is a crucial step in addressing any major failures in the pipeline. Right now, it is only the ego view that can be modified. But I'll eventually extend to all. This results in a final "gt" rrd file. From here, the plan is to improve quality and start building a data loop. Excited to start really scaling this. I'm basically going all in on keeping my data stored as Rerun rrd files. As always, I want to emphasize how crucial it is to LOOK AT YOUR data! The rrd format makes it incredibly easy to do so. Getting the data out to use is a bit of a hassle right now, but for me, it's well worth the tradeoff.
Pablo Vela19,527 次观看 • 9 个月前

✨ Massive Pipeline Refactor → One Framework for Ego + Exo Datasets, Visualized with Rerun 🚀 After a deep refactoring and cleanup, my entire egocentric/exocentric pipeline is now fully modular. One codebase handles different sensor layouts and generates a unified, multimodal timeseries RRD file that you can open instantly in Rerun. --- The first three datasets that are already supported 1. Assembly101 – 4 ego Quest‑style fisheye cams + 8 exo pinhole cams 2. HO‑Cap – 1 ego HoloLens pinhole cam + 8 exo pinhole cams 3. EgoDex – 1 ego Apple Vision Pro pinhole cam Unified geometry: Each frame now logs _both_ camera intrinsics / extrinsics and COCO Whole-Body 133-kp keypoints in the same stream. Everything is canonicalized at import time, so there’s zero OpenCV vs OpenGL guess-work—Rerun reads it all in the correct coordinate system automatically. --- Why this matters - Consistent schema ✚ live visuals – Rerun’s deep link between data & rendering means every experiment comes with a built‑in viewer. No more ad‑hoc OpenCV/matplotlib hacks just to sanity‑check a dataset. - Multi‑terabyte friendly – The next step is bulk‑ingest these giants into Rerun and wrap them in a Gradio UI for point‑and‑click exploration, as I've already done for EgoDex!
Pablo Vela20,836 次观看 • 1 年前
没有更多内容可加载