正在加载视频...
视频加载失败
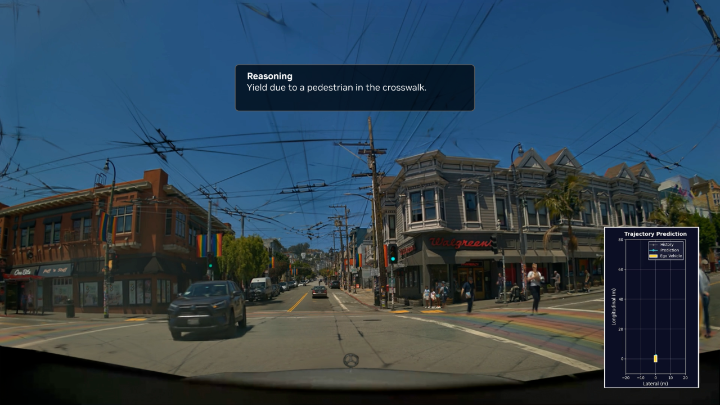
Introducing PAN — MBZUAI’s New World Model for Interactive Intelligence Developed by MBZUAI’s Institute of Foundation Models, PAN is built for simulation, prediction, and agentic reasoning. Unlike traditional video generators that only output frames, PAN maintains a persistent internal state that evolves when guided with natural language. Its Generative... show more

98,725 次观看 • 8 个月前 •via X (Twitter)
0 条评论
暂无评论
原始帖子的评论将显示在这里