Video yükleniyor...
Video Yüklenemedi
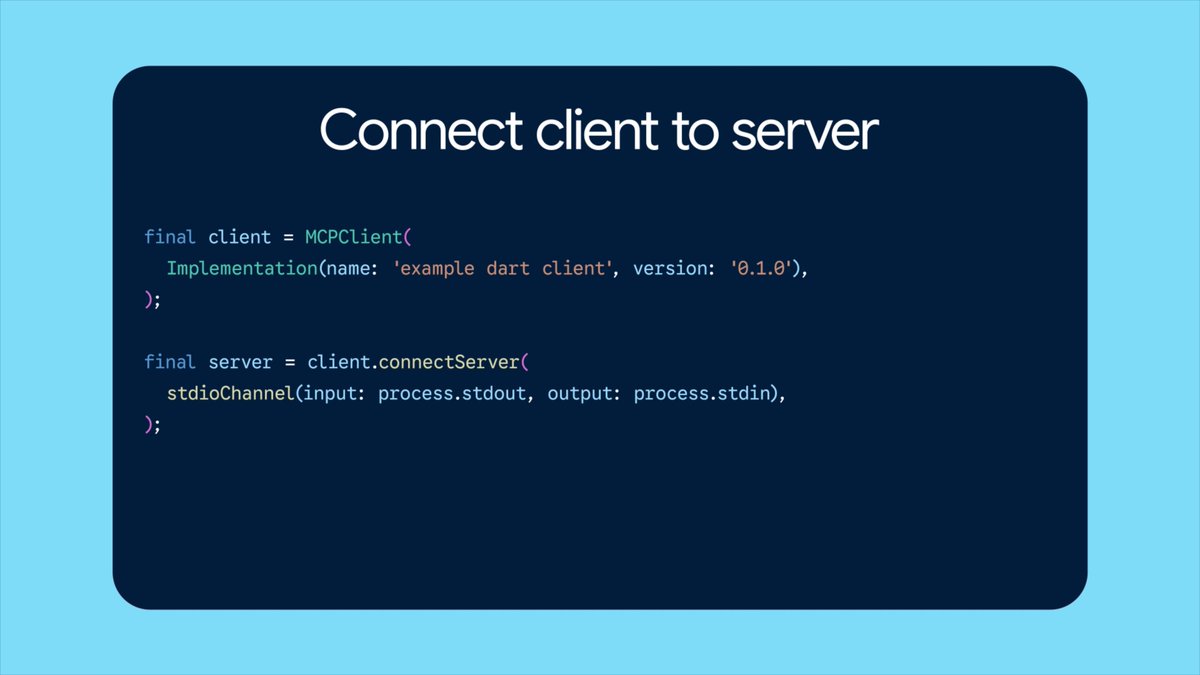
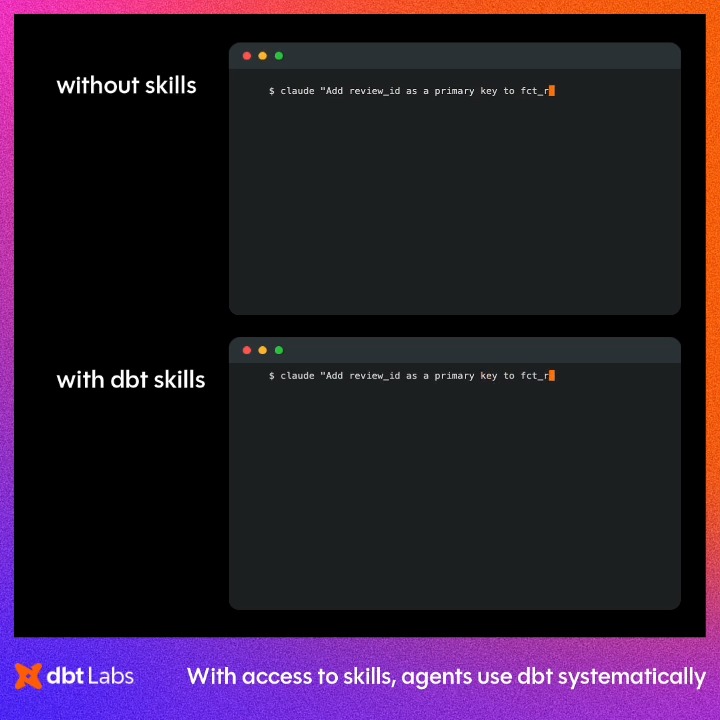
Introducing the context course: a free course on doing ML with agent context. You will learn how to train models, optimize inferences, and build datasets, all by defining harness context with`SKILLS.md`, Plugins, MCP, Subagents, and Hooks. The course includes: - Weekly live AMA on YouTube - Weekly practical projects... show more

16,905 görüntüleme • 1 ay önce •via X (Twitter)
0 Yorum
Yorum bulunmuyor
Orijinal gönderinin yorumları burada görünecek