Video wird geladen...
Video konnte nicht geladen werden
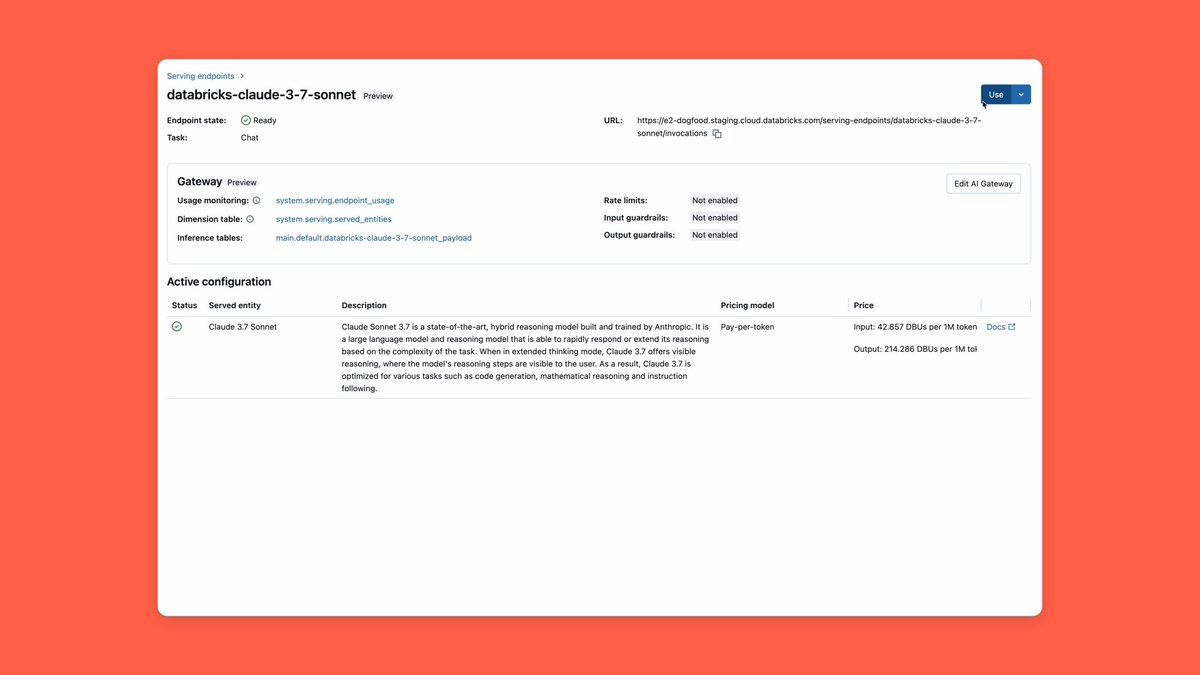
New research from Databricks: LLMs Can Learn to Reason via Off-Policy RL Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL) shows you don’t need strict on-policy training to improve reasoning. It matches or beats Group Relative Policy Optimization (GRPO), stays stable with large policy lag, and uses ~3×... show more

12,539 Aufrufe • vor 4 Monaten •via X (Twitter)
0 Kommentare
Keine Kommentare verfügbar
Kommentare vom Original-Post werden hier angezeigt
















![“But I wish you could explain to me what the hell’s going on with the mind of the public. Because we have the right policy. [Democrats] don’t. They have horrible policy.” —Trump at the House GOP retreat](https://image.24vids.com/tw-2008591960475394512/media/G9_zudDWAAAlt9a.jpg)