Loading video...
Video Failed to Load
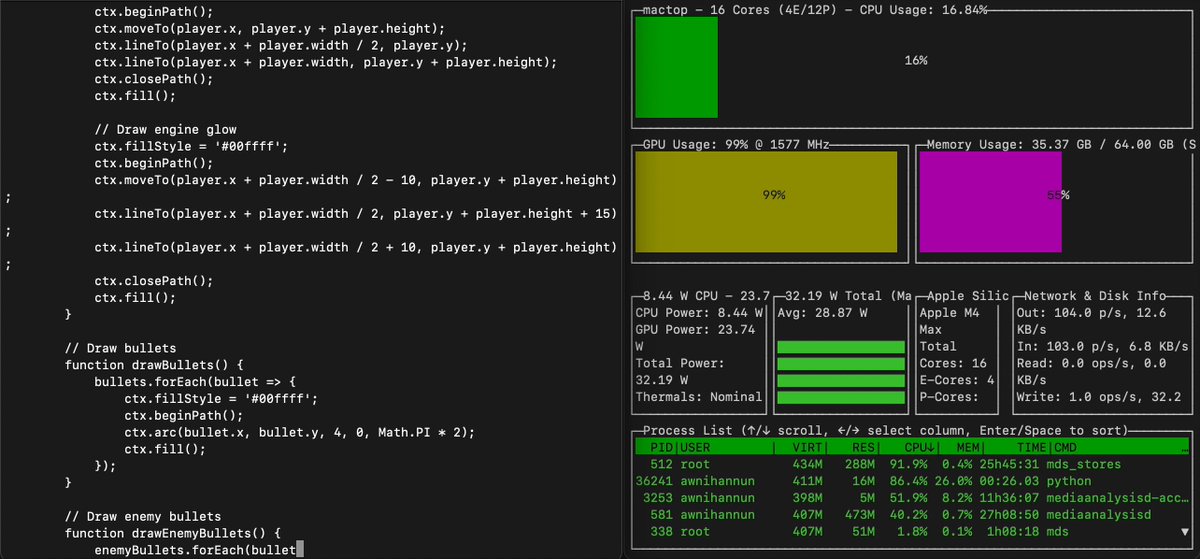
Qwen 32B (4-bit) generates at >40 toks/sec on an M4 Max with assisted decoding and Qwen 0.5B as the draft model. Coming soon to mlx-lm. Compare regular decoding (left) to assisted decoding (right):

50,353 views • 1 year ago •via X (Twitter)
11 Comments

WOW! How does this differ from my speculative decoding impl - what makes it so much faster? Cause this is awesome.

🚀 Don't gamble with your portfolio! Use our advanced hybrid quant risk tool using on/off-chain data daily and make informed decisions. 📈 Acess to 1000+ charts for your crypto journey. 📚Receive free weekly quant analysis. 📊+21 projects supported. 🏗️ Beginners and experts.

Super fast! 💪

Assisted decoding?

A small draft model is used to generate tokens which are then accepted or rejected by the main model depending on certain criteria. In this case the criteria is exact match.

Super cool 🤩

Apple intelligence so far: "siri can set an alarm even faster now!"

Try with the 2b model, set draft tokens to 31, and modify the wording of the prompt to “Write me a quick sort in C++. Don’t give me a preamble, just immediately write the code.” If it’s anything like my tests, I reckon you’ll squeeze a few more tokens/second 😁

Impressive! But do you think one can run diffusion models inference on phones?

Awesome!

Interesting, It makes sense to be faster due to assusted coding definition, however did you try any eval? I wonder what are unpredictable effect of such decoding