Loading video...
Video Failed to Load
Supervised learning has held 3D Vision back for too long. Meet RayZer — a self-supervised 3D model trained with zero 3D labels: ❌ No supervision of camera & geometry ✅ Just RGB images And the wild part? RayZer outperforms supervised methods (as 3D labels from COLMAP is noisy) 🌐... show more

69,527 views • 1 year ago •via X (Twitter)
9 Comments

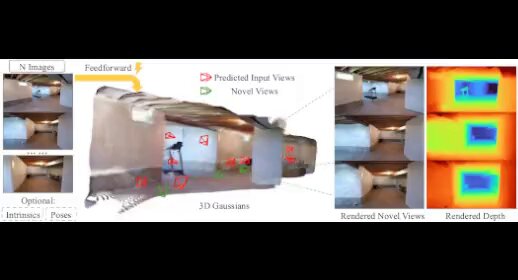
🔍 How does RayZer work? It performs 3D-aware image auto-encoding, which first disentangles images into scene + camera (reconstruction), then re-entangles them back into images (rendering) and learn via RGB loss. The key is splitting the images into two sets — one set to reconstruct scene, and the other to provide supervision, which avoids trivial non-3D solutions.
🤯 RayZer outperforms supervised methods — why? Turns out, 3D labels from COLMAP are noisy. GS-LRM and LVSM consistently fail on scenes of glasses, high luminance intensity, and white walls. These are cases where COLMAP usually fail. This highlights the need for self-supervised learning — and shows just how powerful it can be.
RayZer is similar to video generation models philosophically: ❌ No 3D-aware architecture ❌ No 3D representation & rendering equation ❌ No 3D supervision ✅ But 3D awareness emerges. (We show more inference results)
Joint work with @HaoTan5 @totoro97_ @Haian_Jin @__yuezhao__ @Sai__Bi @KaiZhang9546 @fujun_luan Kalyan Sunkavalli @qixing_huang @geopavlakos

Amazing! Dare to try it in Image Matching Challenge? :)
haha, I don't think it works on images with different lighting conditions now

Super cool. I’ve been looking for pose estimation without any supervision from SfM and couldn’t find any papers! Was super surprised. I’m glad someone finally got this working

cool work!

amazing











![[1/N] Current visual geometry prediction models primarily rely on labeled 3D data. Our CVPR26 paper, Flow3r, allows additionally leveraging unlabeled videos (using flow supervision) for scalable visual geometry learning, enabling accurate multi-view 3D reconstruction in-the-wild.](https://image.24vids.com/tw-2027441878958755968/amplify_video_thumb/2027440939950825472/img/a1KyAlin2ZNvE9QU.jpg)