Video wird geladen...
Video konnte nicht geladen werden
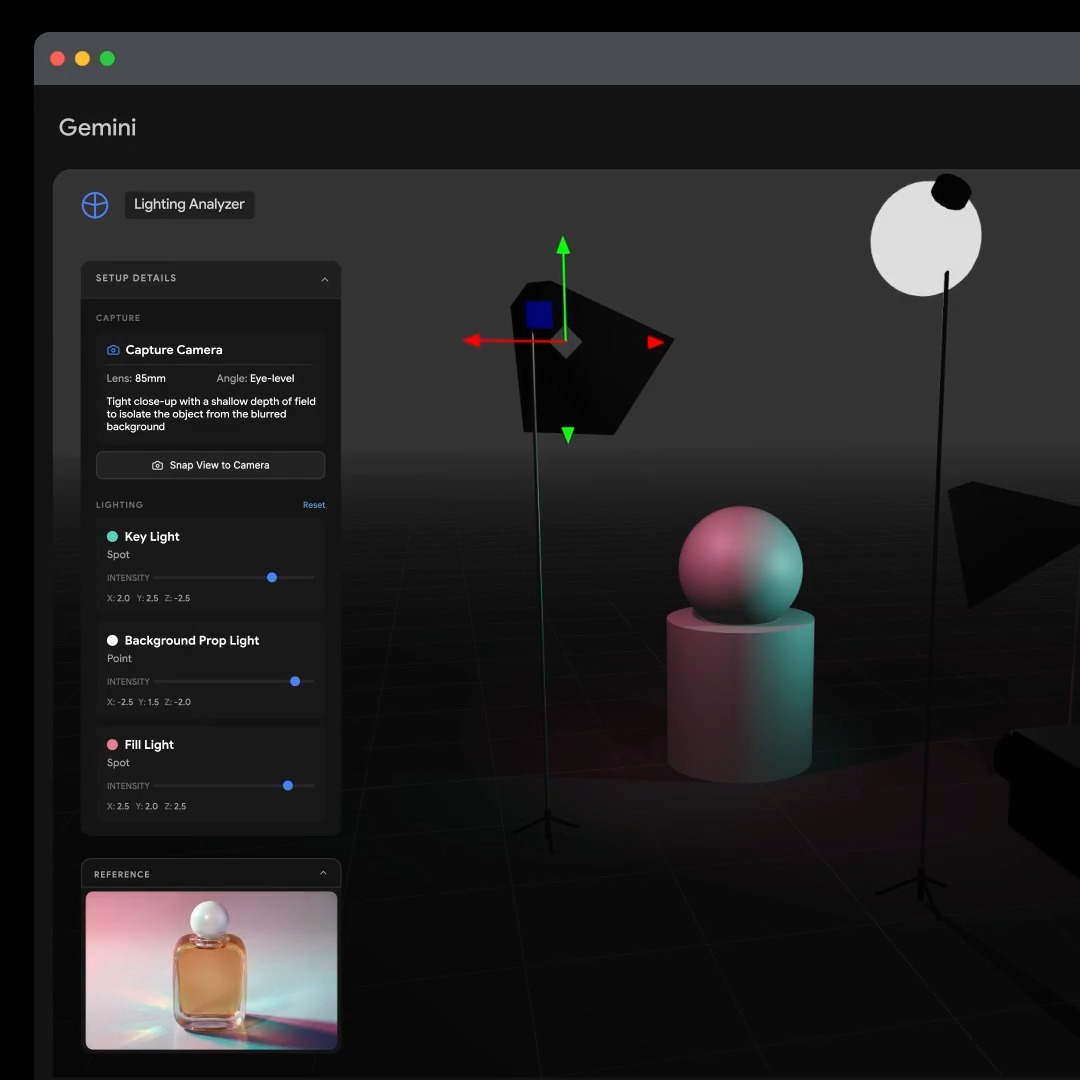
This 3D webpage is highly creative and technically sophisticated. Here are some highlights and details: 1Seamless Scrolling Interaction: Guided by a 3D cat, users can smoothly browse the entire webpage, enjoying a fluid visual experience. ◦Rich 3D Scene Details: ◦Mount Fuji Clouds Unveiling: Presents users with a magnificent opening... show more

10,379 Aufrufe • vor 1 Jahr •via X (Twitter)
10 Kommentare

跟着Rain哥吃肉vor 1 Jahr
自由猫出品 必属精品!!!🎉🎉🎉

Liberty cat Tangvor 1 Jahr
起飞

蓝白色vor 1 Jahr
太炫酷啦,网页是高级的橙色,还有猫猫爪子鼠标,好细节~👍🏻👍🏻

YushiZBWvor 1 Jahr
😻😻

LibertyCats Jamesvor 1 Jahr
细节满满 🤭🤭

Bubble麻花小幸运vor 1 Jahr
太酷啦

123齐步走vor 1 Jahr
细节,实力😻😻😻

Y维David1998vor 1 Jahr
追求极致

songhangxx7vor 1 Jahr
绝绝子

yangj007cn ❤️ LibertyCatNFTvor 1 Jahr
厉害了!