

波妞PONYO
@ponyodong • 12,667 subscribers
AIGC Video Creator & Animation IP Strategist 🐷 前 Peppa Pig China Mktg. 🎨 专注 AI 视觉叙事与漫画 IP 孵化 💡 分享高阶 Prompt 与工作流实战 商业咨询|课程学习 V:PONYODONG
Shorts








Videos

用 ChatCut 剪辑制作_AI 运镜教学视频 一句提示词,Codex 也能直接剪视频了。🎬 这支片用 59 秒讲清 11 种运镜: 摇镜交代空间,跟拍带入行动;俯仰与升降改变力量和尺度;变焦、Dolly Zoom 拉扯注意力与空间;环绕、旋转、手持制造立体、失衡和紧张。 通过 ChatCut 插件,我在 Codex 中完成了本地素材导入、口播策划、字幕生成、MG 封面、章节导航、混音和逐帧检查,所有内容仍可在时间线上修改。 Codex × ChatCut 连接器及操作手册: 直接在 Codex 输入: 安装 安装后可以: 1️⃣ 导入本地视频、音频和图片 2️⃣ 剪时间线,清理口头语与停顿 3️⃣ 转录并生成字幕 4️⃣ 添加 B-roll、转场、叠加层和 MG 动画 5️⃣ 生成画面、旁白、音乐与音效 6️⃣ 导出并检查最终成片 One prompt, one editable workflow—from raw footage to a polished video. #Codex #ChatCut #VideoEditing
波妞PONYO63,663 görüntüleme • 9 gün önce

🚀【喜剧爆款视频教程】投稿得红包🧧 最近刷到一类视频,绝了。 画面看着像 90 年代武侠片,画质糊得一批,配音还是那种译制腔。书生救了一只受伤的白狐,结果美女来报恩的时候说:「公子,我是你三年前吃掉的那只酱板鸭。」 卧槽,这谁能想到。 播放量动不动几百万,评论区全是「哈哈哈哈哈哈」。 我拆解了一下,这套玩法其实不复杂。你品。 【核心就三步】 第一步,画面要正经。 80、90 年代老电影的画质,重颗粒感,低像素,邵氏武侠那味儿。让观众以为在看经典片。 第二步,道具要离谱。 古装场景里突然冒出来一个现代物品。酱板鸭、核弹头、灭火器,什么都可以。违和感拉满。 第三步,反转要极致。 报恩的不是狐狸精,是你当年随手扔掉的那个东西。反转越大,笑果越强。 说白了,就是解构经典。用无厘头的方式消解严肃性,懂吧。 波妞福利【三个剧本,直接用】别忘了来评论区投稿!第一名获得现金💰红包奖励!剧本和提示词见评论区!
波妞PONYO480,045 görüntüleme • 4 ay önce

Seedance 2.5,明天见! 四大核心能力全面升级: 1️⃣ 时长翻倍:单段视频从 15 秒延长到 30 秒,完整对话、连贯动作、小剧情一镜到底,减少因强行切分带来的返工。 2️⃣ 参考素材上限提升至 50 个:人物、服装、场景、道具、动作、声音可同时输入,短剧和品牌内容风格统一更轻松。 3️⃣ 局部精修:手势、道具、背景哪里不满意就改哪里,不用推倒重来整条重生成。 4️⃣ 镜头与空间控制更强:结合动作参考、白模/绿幕,一镜到底、多人互动、打斗、复杂走位都能稳稳拿捏。 这一次,火山引擎携手英格兰传奇球星迈克尔·欧文(Michael Owen),用 Seedance 2.5 重现他职业生涯的高光时刻——从标志性招牌动作,到天马行空的创意演绎,豆包视频生成模型正在不断拓展 AI 视频创作的边界。 #火山引擎 #Seedance #迈克尔欧文 #美加墨世界杯 #AI电影
波妞PONYO19,964 görüntüleme • 6 gün önce

说个我做了大半年AI 漫剧踩过的坑: AI短剧拍多人戏,最容易崩的根本不是画质,是一换机位人物就全乱了。 你想啊,上一秒三个人好好坐在茶桌前,左边右边都对得上,镜头一切过肩,好家伙,位置、视线、桌子、背景,模型跟失忆了一样,全部重新脑补一遍。 试了好多次才想明白,问题不是提示词写得不够华丽,是根本没给AI一个“稳定的空间”去理解。 这次用的是LibTV的3D导演台,流程大概是这样:先画一张多人站位图,角色、桌子、背景的相对位置先定死;把这张图丢进3D导演台,变成一个能转能换机位的空间蓝图;在这个空间里随便切全景、近景、过肩、俯拍、低角度,怎么切都不乱;最后把这些机位截图转成真实古风剧照,再从剧照生成视频。 说白了核心就一句话:别让模型每次都从一句话里“凭空想象”场景,先把空间关系锁死,剩下的画面质感、表演、运镜交给模型就行。 这样人物不会飘,桌子不会跑偏,镜头切换是真的像有导演在调度,而不是一张张抽卡拼出来的。 我感觉这才是AI短剧从“好看的一张图”往“能讲故事”迈出的关键一步。 7月8号周三晚上8点,我会开一场直播,把整套流程从头到尾拆给你们看。想进群的加微信ponyoassist。
波妞PONYO20,871 görüntüleme • 14 gün önce

Seedance 2.0 x周星驰官方授权来了!! 火山引擎×比高集团合作,《喜剧之王》《长江七号》《食神》经典IP全部开放AI二创 🎬 在即梦上就能用,合法合规,创作者狂喜!为大家详细分析了即梦后续关于明星授权二创的打法😆
波妞PONYO36,409 görüntüleme • 27 gün önce

想做 AI 漫剧?先搞懂最大难点:场景调度 你有没有发现,AI 做多人打斗视频的时候,最容易乱的不是招式。而是人物一多,镜头就不知道该跟谁,空间也开始对不上。 这条视频我想讲的就是一个很实用的方法: 先不要急着写“飞身、挥刀、闪避”这些动作词。 先把场景画成一张 3D 俯视动线图。 谁从哪边进来,镜头从哪里推进,危险点在哪里,人物最后要往哪边走,都先在图上定清楚。 这样 AI 生成的时候,它拿到的就不是一句模糊的“打一场很燃的戏”,而是一张能拍的导演地图。 多人打斗想不乱,第一步不是加动作,是先控场。 这条可以当成一个小方法,以后做动作戏、舞蹈戏、多人调度都能用。 #AIGC #AI导演 #即梦AI #AI短片 #场景设计 #分镜设计
波妞PONYO12,737 görüntüleme • 12 gün önce

如何用 Fable 5 去宠物赛道搞钱? 这条广告片里,没有一只真实拍摄的狗,没有一件真实存在的衣服,连"the peeet"这个品牌都是现造的。 logo、产品海报、电商详情图、六宫格分镜,到最后这条30秒成片——四张图加一条视频,提示词全部是 Fable 5 帮我一步步理出来的,再交给生图生视频模型跑,零实拍、零打样。 我在宠物用品这个赛道上测试的不是衣服好不好看,是"用AI把一个品牌从0跑到广告片"这条路能不能走通。验证一个电商品类值不值得做,门槛从"囤货拍照"变成了"把提示词理顺"。 你家有毛孩子吗?要不也试试为毛孩子设计的宠物用品呢? #Fable5 #AI搞钱 #宠物经济
波妞PONYO17,210 görüntüleme • 19 gün önce


【爆笑喜剧拆解第二弹】邵氏武侠+谐音梗,为什么能火? 先说结论:不是技术牛,是反差感抓人。 80 年代港片画面,配上土味谐音梗,一本正经地胡说八道。这种错位的幽默感,让观众停不下来。 怎么拍?三步走 画面:用 AI 生成邵氏风格,`Shaw Brothers style` + 颗粒感滤镜。复古画质能掩盖 AI 瑕疵,反而更有味道。 内容:找成语谐音。危机四伏→危机 4 伏(四只鸡),傻了吧唧→傻了 8 鸡。越正经的画面,配越离谱的台词,效果越好。 钩子:结尾抛个问题。「鸡鸭鹅背着鸡,聊什么?」答案是「叽叽喳喳(鸡鸡扎堆)」。诱导评论互动,算法自然给流量。 --- 工具链 画面:即梦 / 可灵/Sora + 复古滤镜 配音:剪映译制腔 + 电流麦音效 对口型:LivePortrait / Hedra 剪辑:剪映加噪点、做旧处理 --- 核心逻辑 邵氏美学提供情怀分,谐音梗提供传播点,竞猜钩子提供互动率。 AI 降低了画面门槛,真正的门槛是「找梗能力」。 三个谐音剧本放在评论区,大家可以去玩一下试试看。
波妞PONYO65,331 görüntüleme • 4 ay önce

【实战技巧】兄弟们,剪映的运镜指令,我用 AI 全复刻了 上周甲方发来一条剪映做的片子。问我能不能做出同款运镜效果。我说可以,但不用剪映。 16 张静态照片,全用 Seedance 2.0 生成,最后剪出来的片子,他以为是摄影师拍的。 剪映的运镜为什么这么香? 剪映的运镜模板火是有原因的。 它把专业的摄影术语翻译成了普通人能理解的选项: 推镜头 → 放大特写 拉镜头 → 展现全景 环绕 → 360 度旋转 上帝视角 → 俯拍 跟拍 → 跟着主体移动 点一下就能用,不需要懂摄影。但 Seedance 2.0这种 AI 工具不一样。它没有可视化界面,你得用文字告诉它「摄影机怎么动」。大部分人卡在这一步。 他们不知道: 推镜头的英文术语是什么? 运动幅度该设多少? 什么场景用什么运镜? 所以我写了这篇文章。 把剪映里那些常用的运镜指令,全部翻译成 Seedance 能理解的提示词。 #Seedance2 #图生视频 #运镜指令 #提示词教程
波妞PONYO63,980 görüntüleme • 5 ay önce

好久没给大家撰写我精心设计的视频提示词了,今天就来一把大的。把镜头当成一颗子弹,打进了一座“活着的废城”——《蚀城突围》 Corroded Skyline: Biomech Breakout 这支 30 秒短片,起初的构想并不是普通科幻战斗, 而是一种失控的沉浸感: 超广角 FPV 疾冲、酸雨、爆炸、坍塌城市、 被有机生长吞噬的摩天楼、 重装机甲小队和变异生物机械军团正面交火。 最爽的是后半段—— 镜头从战场贴地穿梭,突然拉升, 俯瞰整座被战争撕开的生物朋克废土城市, 最后冲向天空,把末日战场甩在身后。 这可能是我最近做得最有“大片感”的一支 AI 概念视频。 技术、腐朽、机甲、速度和噩梦感,全都揉在一起了。 下一步我想把它扩成一个完整世界观。你觉得怎么样? #AIvideo #AIFilm #SciFi #Mecha #Biopunk #FPV #ConceptArt
波妞PONYO15,019 görüntüleme • 1 ay önce


☺️今天是我的生日。送给自己的礼物是,让 RINO 第一次跟世界打招呼🥰 不是"游戏变玩具"。 而是——一次冒险,被收藏下来。 做了两版赛博HUD转场,蓝色数据隧道,做完感觉俗了,全删。 换了一个方向: 一本旧冒险档案被翻开 手绘地图开始流动 RINO 从纸面里醒来 走进遗迹,找到 relic 最后被盖章认证——变成收藏级潮玩 这一下,顺了😆 这是 PONYO Rogue Crew 的第一位成员。 RINO,Relic Hunter。 她的任务,是把被遗忘的故事捡回来。 感觉她终于有点活过来了😊 #PONYO #RINO #PONYORogueCrew #DesignerToy #BlindBox #CharacterDesign #AIGC #AIArt #AIVideo
波妞PONYO19,678 görüntüleme • 1 ay önce


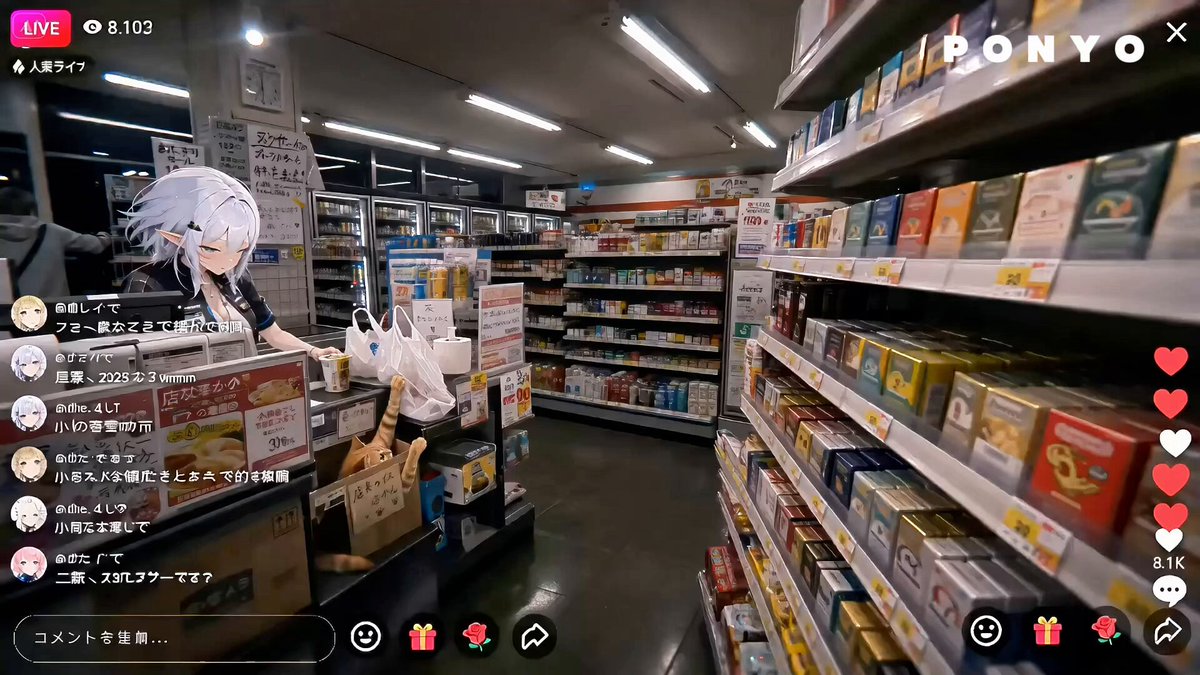
女主播上岗计划|大家好,我是雾岛澪,24小时便利店夜班实习店员,编号 N-07。 今天是我上班的第二天。 本来我的任务很简单:补货、理货、贴折扣标签、不要把货架弄乱。 但是现在情况有点失控…… 我只是想把饭团和零食摆回原位,结果橘猫店长突然跳进纸箱,又把 30% OFF 的标签扒下来了。 货架上的东西开始掉,饮料滚到地上,零食也散了一片。 我正在努力假装自己很冷静。 但其实我已经不知道先抓猫,还是先救便当了。 今晚还在直播。 如果你路过我的直播间,可以进来帮我解决一下: 这只橘猫到底算同事,还是算工作事故? 顺便,谁能告诉我—— 便利店夜班第二天就遇到这种情况,是正常的吗? #二次元打工实录 #雾岛澪 #KirishimaMio #AnimeWorksHere #ChatGPTImage2 #AIArt #AIGC #便利店夜班 #橘猫店长
波妞PONYO13,841 görüntüleme • 1 ay önce

有件事我想说给潮玩行业的人听—— 以前从0做一个潮玩 IP,要经历:概念设计、建模、渲染、拍摄、剪片、做宣发……每一步都是时间和人力。 现在我一个人,用 AI,把这套流程全跑了一遍。 从角色设计、海报包装,到发布短片——从创意到成片,周期短到离谱。 这不是说 AI 把设计师替代了。是说会用 AI 的设计师,现在可以一个人撑起一整条 IP 内容线。 POP MART 52TOYS_US @TOPTOYofficial 六分の一が好き Kidrobot SUPERPLASTIC 你们在找下一个能独立运转的创作者 IP 吗? 我在。 PONYO Studio / Outlaw Bloom SS.26 #DesignerToy #AIDesign #PotentialCollab #PONYO #潮玩 #盲盒
波妞PONYO12,719 görüntüleme • 1 ay önce

兄弟们,新作品来了—— 《CAN YOU HEAR ME?》,这是我第一次给 PONYO SIGNAL GIRLS 做 MV。音乐是我自己写的,灵感来自英国的车库音乐。从有这首歌的想法到现在,一直有一个画面在脑子里:一个人坐在深夜的车里,问一句"你能听见我吗",不知道有没有人接收到。 我想让虚拟角色有重量,不是漂在天上的,而是能跟真实世界待在同一个空间里。 她是 CHANNEL 05,Signal Girls 的其中一个成员。 其他人在哪儿?在路上了。 世界观还在建,但她已经在了。先听听这首歌。 感谢黄总huangserva对音乐事业的大力支持♥️ 🎵 CAN YOU HEAR ME — PONYO SIGNAL GIRLS MV-001 / SIGNAL BROADCAST SYSTEM
波妞PONYO11,097 görüntüleme • 1 ay önce

【奥义书-最后的代码武士】 当刀锋遇上算法,谁在定义这个赛博江湖? 听见了吗? 那是暴雨打在黑色盔甲上的回响, 还是显卡全速运转时风扇的低鸣? 在这个由 0 和 1 构建的赛博荒原,古老的武士道并未消亡,它进化了。 我们将“心、技、体”的修炼,化作《武士奥义书》中严谨的 Prompt 矩阵。 晶核生成,是心决,锁定万物之源; 动态赋予,是身法,即使静止亦有雷霆之势; 工业剪辑,是招式,在毫秒之间斩断无序的杂讯。 这一刀,不仅是为了斩断平庸,更是为了在 chaotic 的数据海洋中,开辟出一条通往极致美学的道路。 身在代码丛林,心怀古道热肠。 做那个在算法洪流中, 依然握紧手中“刀”的人。 致——最后的代码武士。 #AIArt #Cyberpunk #SamuraiSpirit #SKILL #CLAUDE
波妞PONYO17,671 görüntüleme • 6 ay önce

🐍【从电影《青蛇》复刻AI 视频微表情】 先说我的研究结论,AI 根本不懂“悲伤”。 你写“她很悲伤,但在克制”,它只会给你一张标准哭脸。我试了 200 多次才意识到问题不在提示词写得不够“文艺”,而在于——AI 从来不理解情绪,它只识别“物理证据”。“悲伤”“隐忍”“克制”这些词,对人类来说有画面,但对 AI 来说是空的;它真正能读懂的,是眼睛开合多少、有没有泪、嘴角移动了几毫米。你以为你在描述情绪,其实你在给一个只认像素和结构的系统下达无效指令。 后来我拿《青蛇》里一段 39 秒的镜头,逐帧拆出了 6 个微表情节点,才慢慢摸到一套“翻译方法”: 把所有情绪词,翻译成可被观察的细节。核心其实就四件事——用“位置”替代“感觉”,用“数值”替代“程度”,用“对比”替代“绝对”,以及找到那个唯一的“泄露点”。真正难的不是哭和笑,而是“绷住”:整张脸几乎静止,但总有一个极小的地方泄露了情绪。比如“含泪克制”,不是一脸悲伤,而是全脸不动,只有一滴泪落下;比如“冷然嘲讽”,不是明显的冷笑,而是右嘴角比左边高不到 1mm,但那个微差已经足够传达判断和距离感。 所以关键结论很简单:AI 不懂“克制的悲伤”,但它能理解“眉毛放松 + 眼睛湿润但不落泪 + 嘴巴中性”。这不是写作技巧的问题,而是认知方式的切换——你不再写情绪,而是提供证据。从今天开始,放弃那些抽象词汇,把每一种情绪都拆成可见的细节。你会发现,不只是 AI 更听话了,你自己对“表情”和“情绪”的理解,也会彻底升级。 你想了解完整的《波妞AI导演课:棱镜世界》的微表情拉片课,可以进群咨询ponyoassist
波妞PONYO12,631 görüntüleme • 4 ay önce