Загрузка видео...
Не удалось загрузить видео
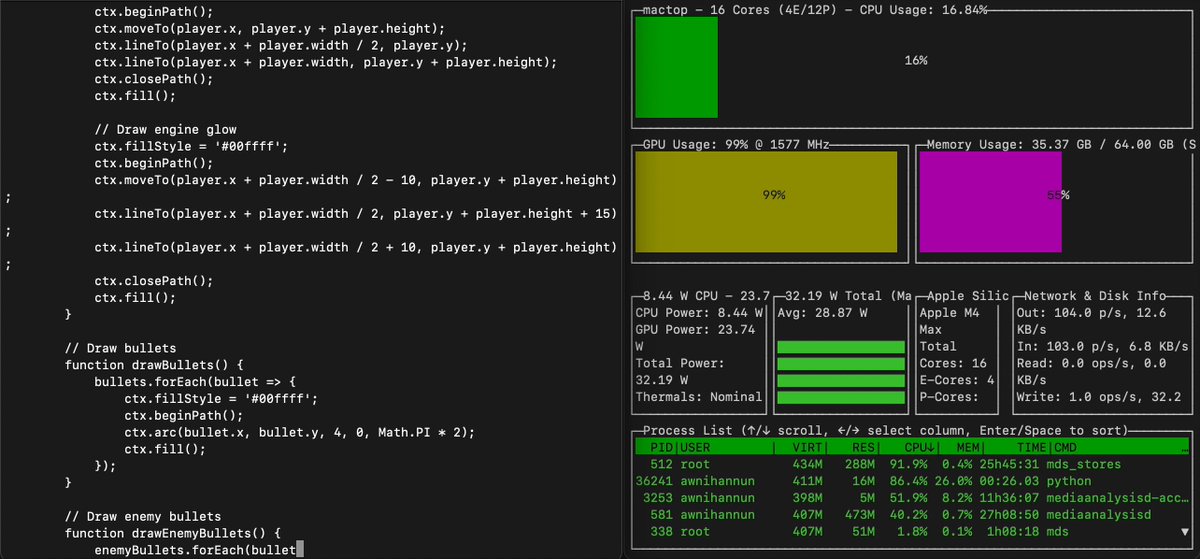
For even higher throughput and lower latency: batch generation + tensor parallel with mlx-lm + and mlx.distributed. Here it's generating at 63 tok/sec (throughput) with GLM 4.7 in 6-bit and batch size 4 on 4 M3 Ultras:

22,721 просмотров • 7 месяцев назад •via X (Twitter)
Комментарии: 0
Нет доступных комментариев
Здесь появятся комментарии из оригинального поста