Loading video...
Video Failed to Load
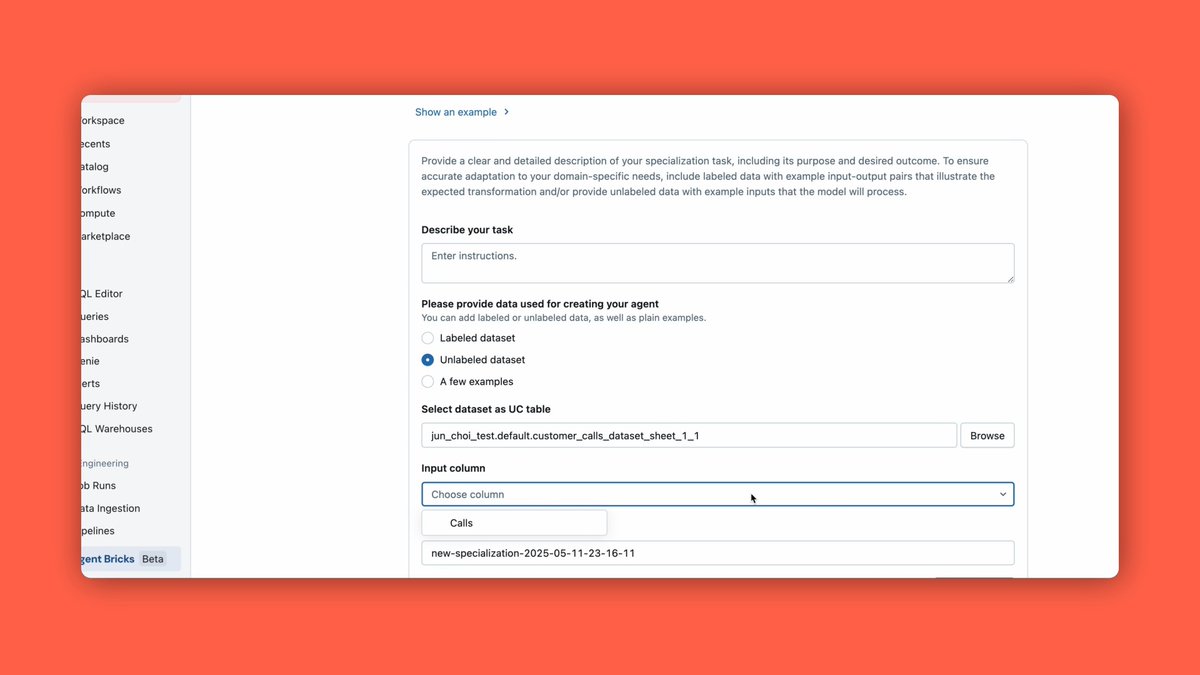
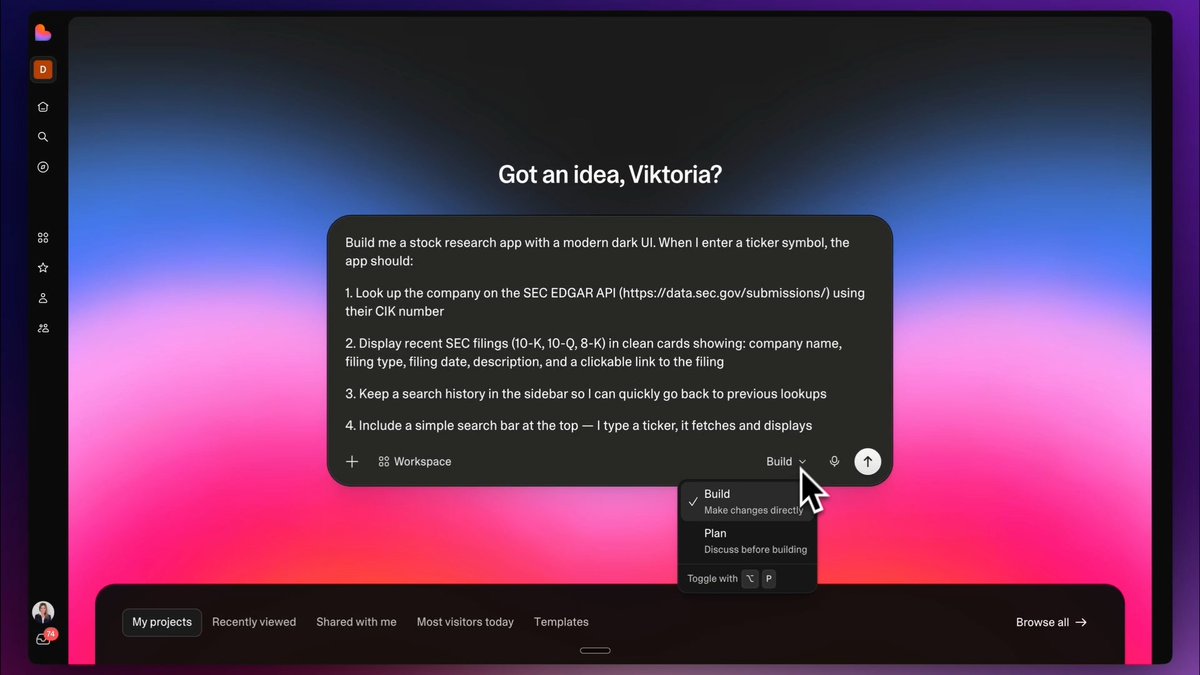
Introducing Databricks Document Intelligence: a research-specialized layer that turns raw enterprise documents into structured data your agents can actually reason over. Across our benchmarks, Document Intelligence delivered the highest end-to-end parsing and extraction quality at 6-8x lower cost, with a 16% average performance gain across every agent framework tested,... show more

19,428 views • 3 months ago •via X (Twitter)
0 Comments
No comments available
Comments from the original post will appear here