正在加载视频...
视频加载失败
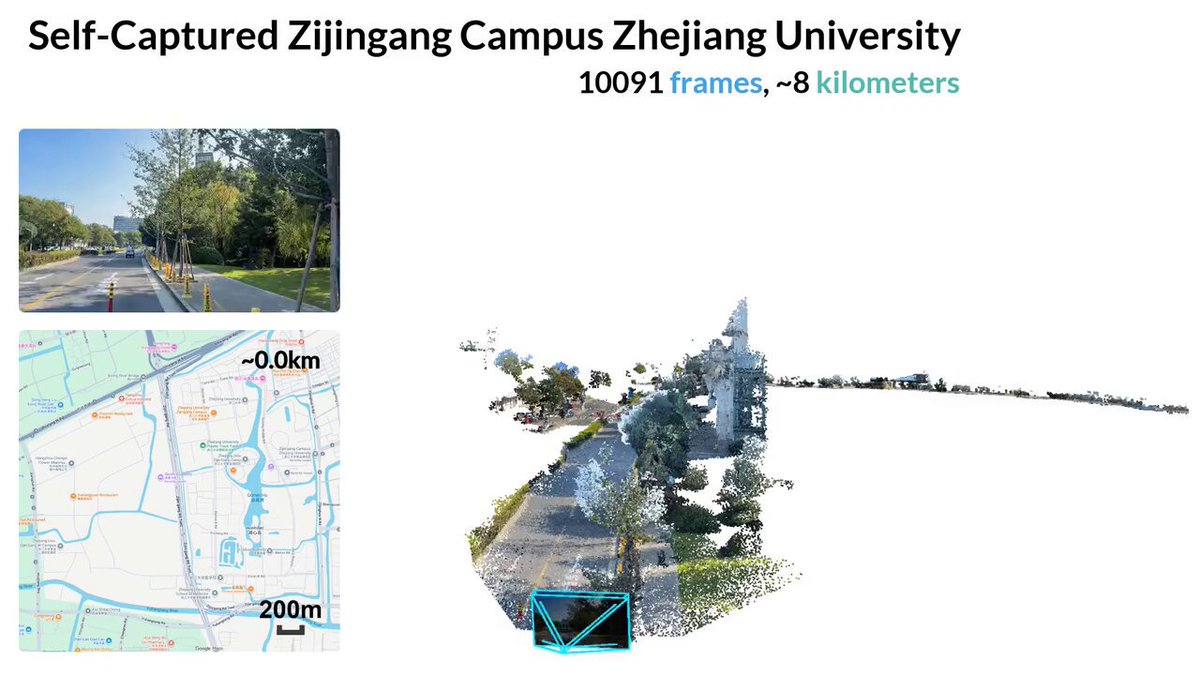
Introducing VGGT-Ω: scaling feed-forward reconstruction across static and dynamic scenes, and studying whether the learned geometric representations transfer beyond reconstruction.

0 条评论
暂无评论
原始帖子的评论将显示在这里
正在加载视频...
暂无评论
原始帖子的评论将显示在这里