正在加载视频...
视频加载失败
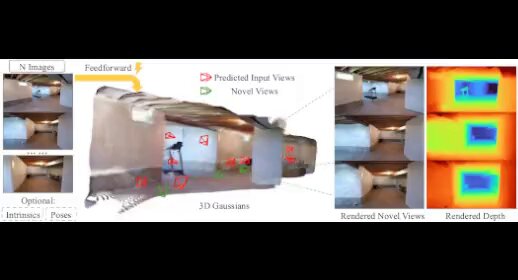
📢 Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation Got only one or a few images and wondering if recovering the 3D environment is a reconstruction or generation problem? Why not do it with a generative reconstruction model! We show that a camera-conditioned video diffusion model can... show more

0 条评论
暂无评论
原始帖子的评论将显示在这里