Loading video...
Video Failed to Load
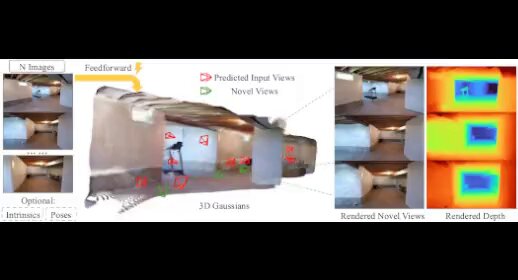
MeshLRM Large Reconstruction Model for High-Quality Mesh We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on

69,111 views • 2 years ago •via X (Twitter)
5 Comments

NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by
simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute.
Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation.
paper page:
daily papers:







![[SIGGRAPH 2025] Photoreal Scene Reconstruction from an Egocentric Device Contributions: 1. We address the importance of employing visual-inertial bundle adjustment (VIBA) that accounts for the rolling-shutter behavior of the RGB camera. This provides a continuous camera trajectory to model pixel movement in neural reconstruction. Our experiments demonstrate that using VIBA consistently improves the novel view quality in Gaussian Splatting by +1 dB in PSNR. 2. We introduce a rasterization-based image formulation pipeline that addresses common artifacts in physical image formation, including rolling shutter, lens shading, exposure, and gain compensation. Our approach is distinct in that we represent image poses as posed pixel arrays sampled from a continuous trajectory, rather than assigning a single camera pose per image, and preserve the merit of Gaussian rasterization. Unlike existing methods that require ray-tracing Gaussians, e.g., [Moenne-Loccoz et al. 2024], our formulation is applicable to general-purpose rasterization-based Gaussian splatting. When applied to 3D Gaussian Splatting (3DGS) [Kerbl et al. 2023], our approach can further enhance reconstruction quality by +1 dB. We outperform existing baselines and demonstrate a substantial quality improvement in handling complex scenes observed by egocentric devices. 3. To reduce the effect of blur from rapid head motion in darker indoor scenes, we propose a strategy of deliberately underexposing input videos during capture, inspired by HDR+ [Hasinoff et al. 2016]. We demonstrate that we can reconstruct high-quality, noise-free scene radiance from noisy, dim input videos, and further render sharp, blur-free videos at a higher dynamic range.](https://image.24vids.com/tw-1930869546531074148/amplify_video_thumb/1930869490562293760/img/AMxv5TbQ_LRSOLJz.jpg)

![[SIGGRAPH '25] TeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling Note: On the left that's a 3DGS rendering! Contributions: 1. We propose a simple approach for rigging 3D Gaussians within the continuous tangent space of 3DMM face models, allowing Gaussians to move freely across mesh triangles. 2. We propose a novel CNN-based deformation model that is agnostic to the number of 3D Gaussians, naturally enabling adaptively densification of the representation to improve detail where most needed, with expression-dependent shading. 3. We show significant improvements over baseline SOTA methods and demonstrate the ability to render even extreme close-up images at high quality.](https://image.24vids.com/tw-1921787265812189187/amplify_video_thumb/1921787215073718272/img/7XpTmvPJuxR3Ac8e.jpg)