正在加载视频...
视频加载失败
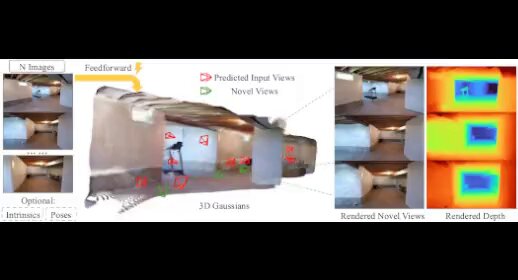
📢📢📢 𝐀𝐂𝟑𝐃: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers TL;DR: for 3D camera control in generative video, it really helps knowing *which* part of your model you should mess with Internship by Sherwin Bahmani at Snap

5 条评论

TL;DR (expanded): 1) "when" in the diffusion process you condition for camera matters (i.e. noise scheduler) 2) "how" in the diffusion process you condition for camera maters (i.e. architecture) 3) "what data" you give to your diffusion model to condition camera matters
Why, you ask? 1) camera motion is low-frequency... early denoising iterations deal with low-frequency content 2) early DiT blocks are enough to fine-tune for camera control... more and you lose quality 3) model needs to know what a static view of the dynamic world looks like
A shout to the collaborators @isskoro @guocheng_qian A. Siarohin @willimenapace @SergeyTulyakov at Snap and @DaveLindell at UofT.

@sherwinbahmani Congrats @sherwinbahmani !!

@sherwinbahmani Congrats to the team ! Amazing work










![📢 PART 1__[The Making of an UnderClass] with Dr. Claud Anderson_ "Major societies in this country have ways of excluding you intentionally without you knowing it."](https://image.24vids.com/tw-1882120554263847165/ext_tw_video_thumb/1882120273240961024/pu/img/bTmtW_l-yTgIkaef.jpg)




![✨ Made a new mini feature on Photo AI: [ Grab from 3d model ] So the problem is we're at that stage in time (typical for AI) where image-to-3d models are not good enough but are fun to play with, but we know they'll be good enough in 1-2 years With [ Make 3d model ] you already can turn any Photo AI pic into a 3d model but it still looks hyper clunky and deformed, but it works! One cool idea I had to make that more useful and made now: Let people make a 3d model then change the view of the it with the 3d viewer, then press [ o ] and it grabs a frame of the 3d That image you can then [ Remix ] (img2img), and it becomes a real photo again and that in turn you can then turn into a video again with [ Make video ] So that essentially gives you a fully freeform camera position control to take photos with One thing I need to fix is the background/skybox, I kinda need to take the original photo and remove the person and just get the background for the 3d model viewer, in this case it should be white, but it's a start!](https://image.24vids.com/tw-1940749265615179946/amplify_video_thumb/1940747973064822784/img/P___fqKPPJyKeVwq.jpg)

